【Flowchart Mode】How to set the fields | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial will show you how to set fields in flowchart mode. No Programming Needed. Visual Operation. ScrapeStormFree Download
“Extract” component is used to extract data from a web page. The component can be used alone or in conjunction with a “Loop” component or a “Judge” component. It is suitable for extracting data on a single page when used alone. When used together, it is suitable for extracting data on all pages.
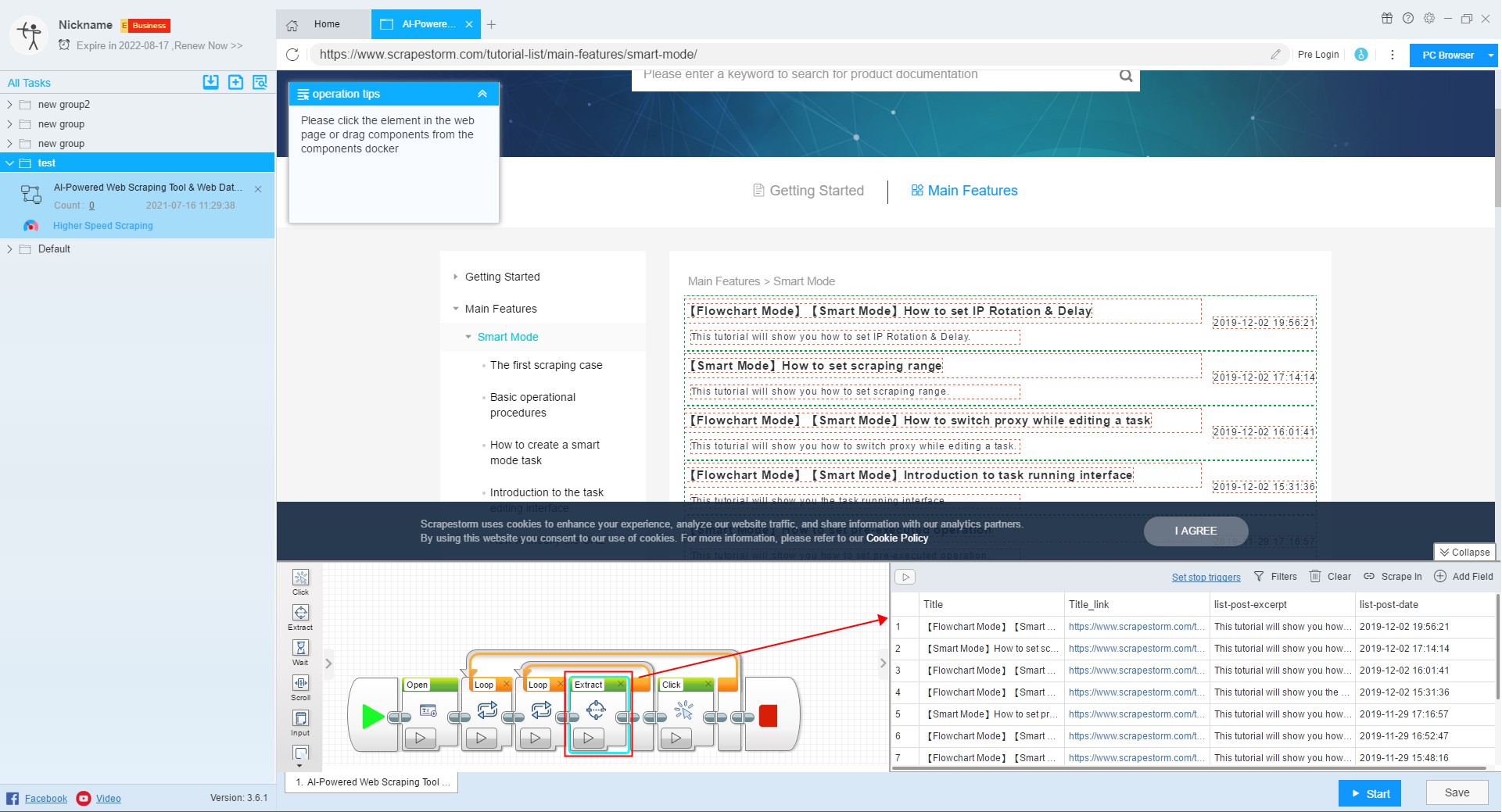
The specific settings are as follows:
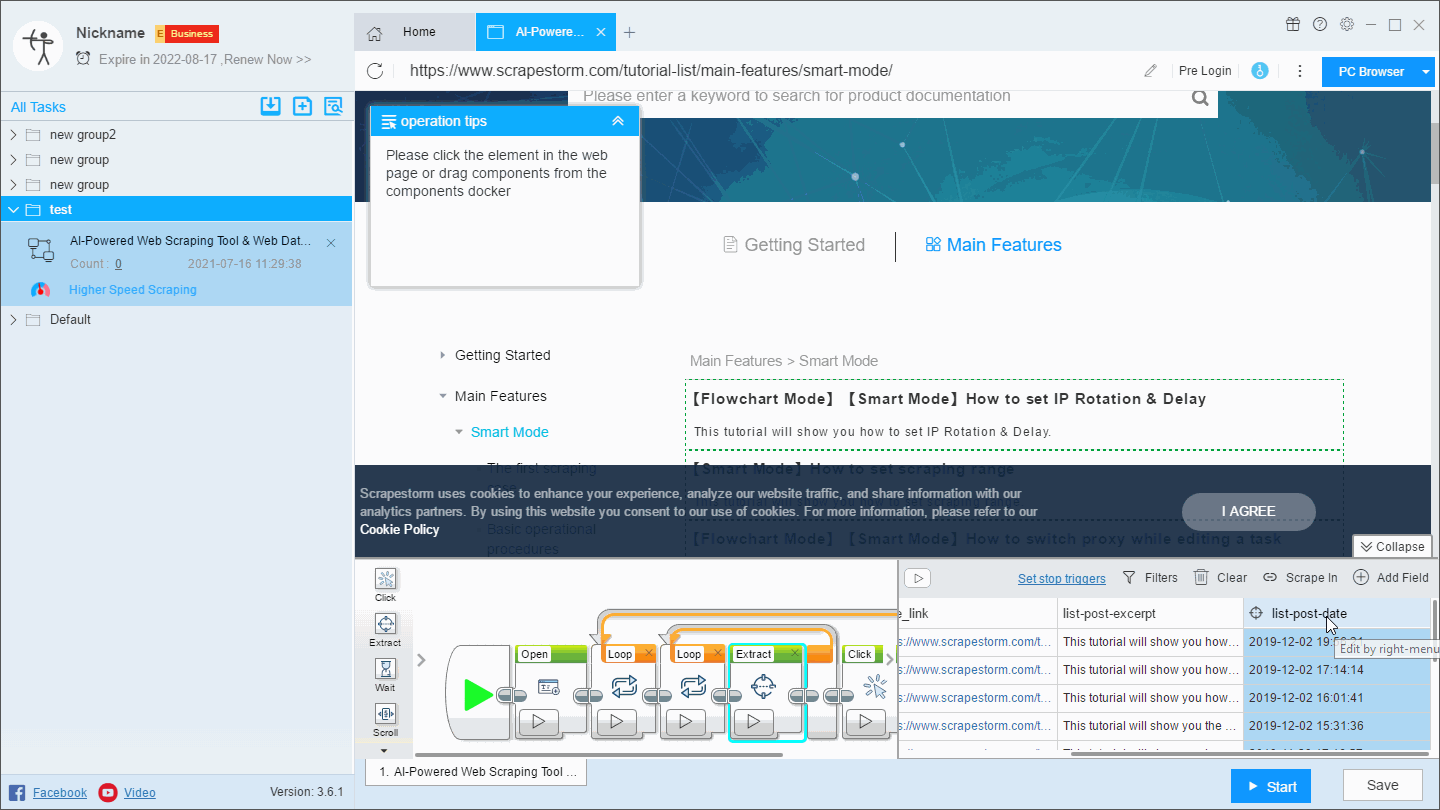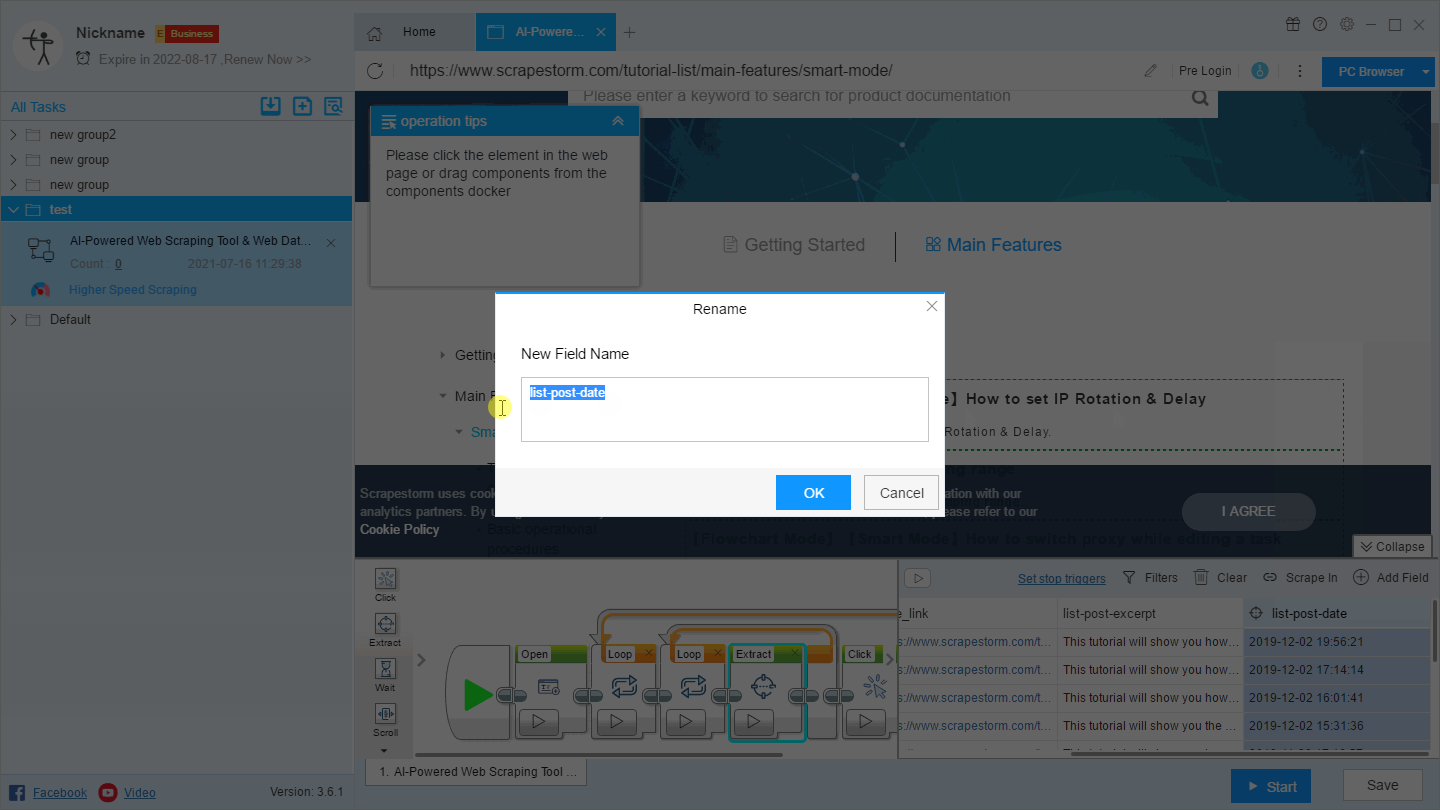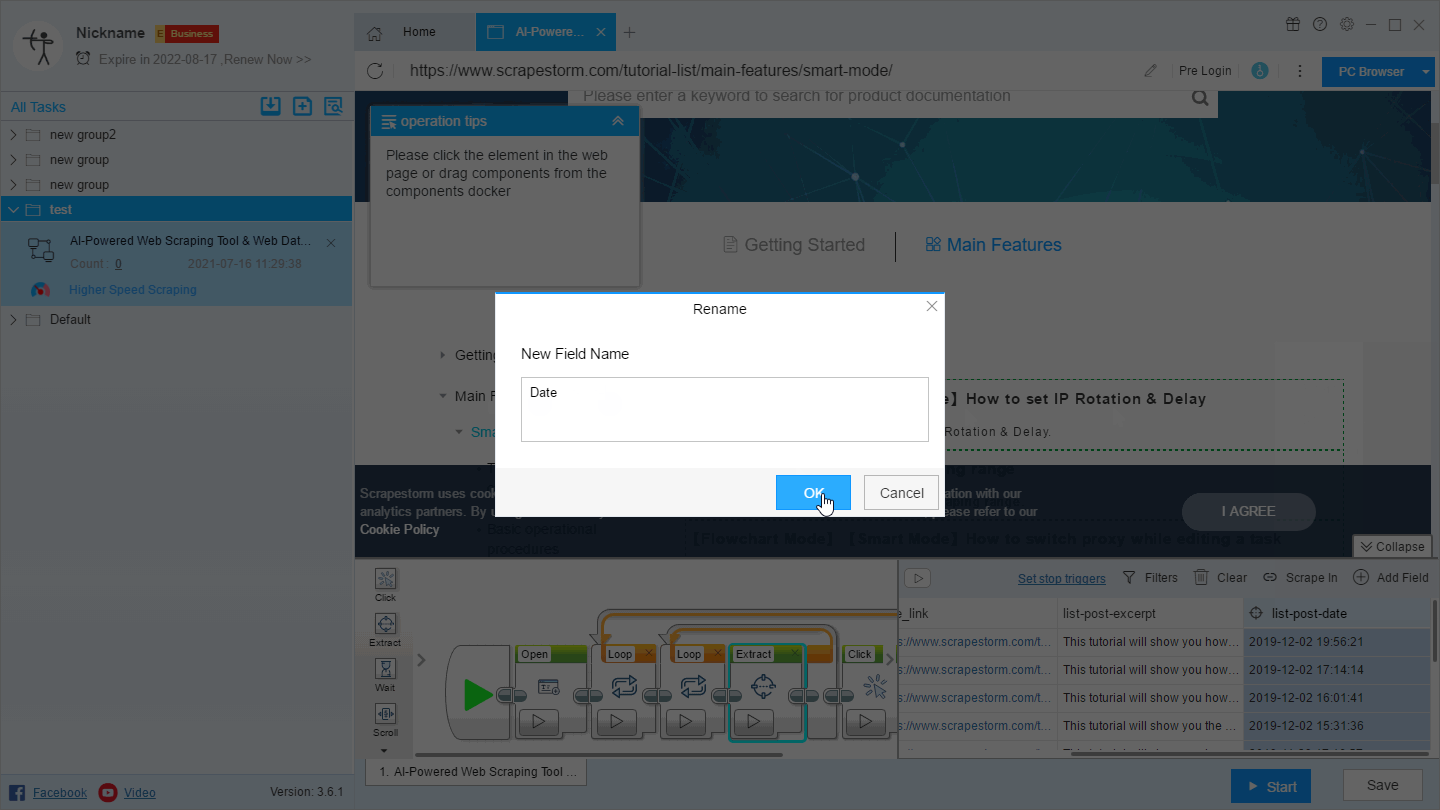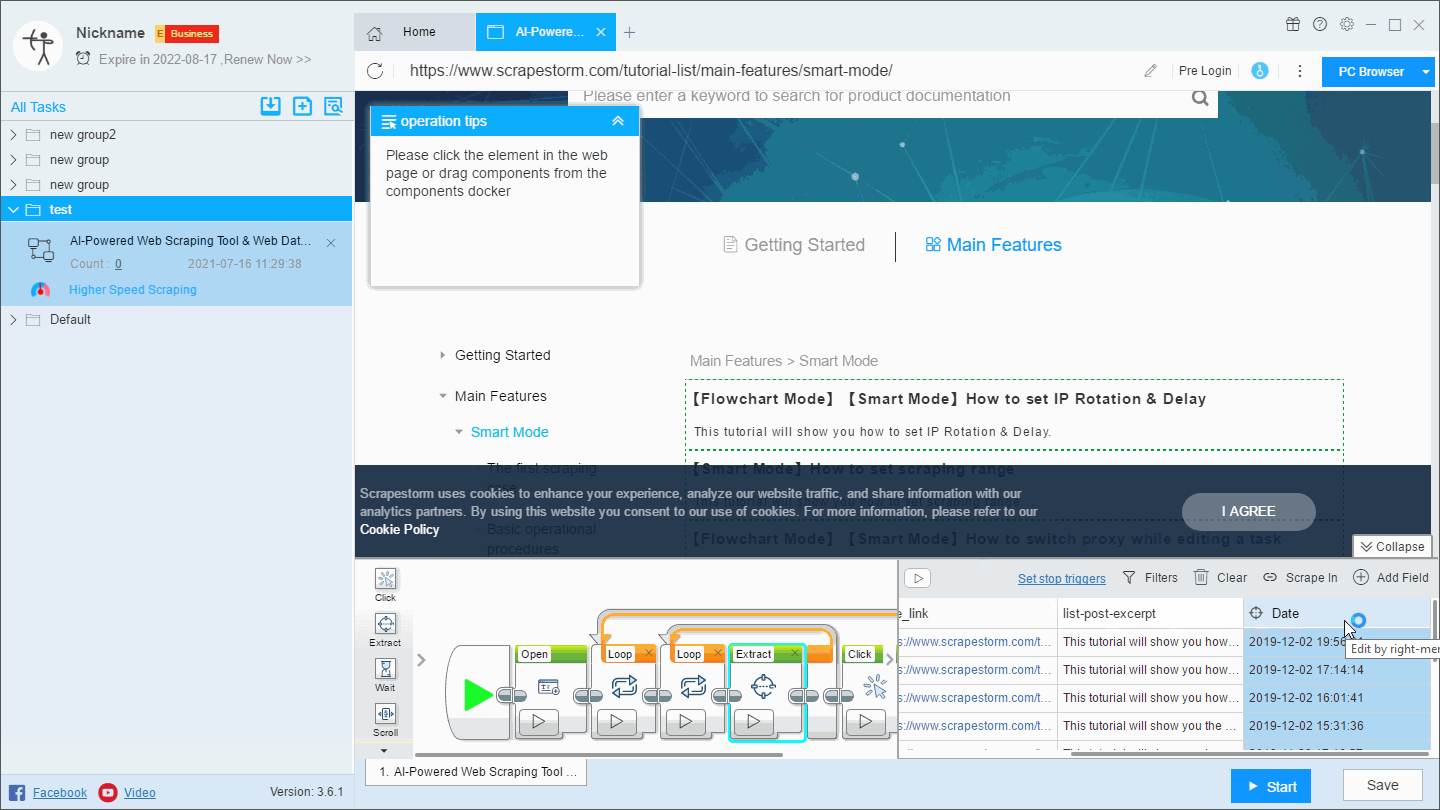
1. Rename
2. Merge
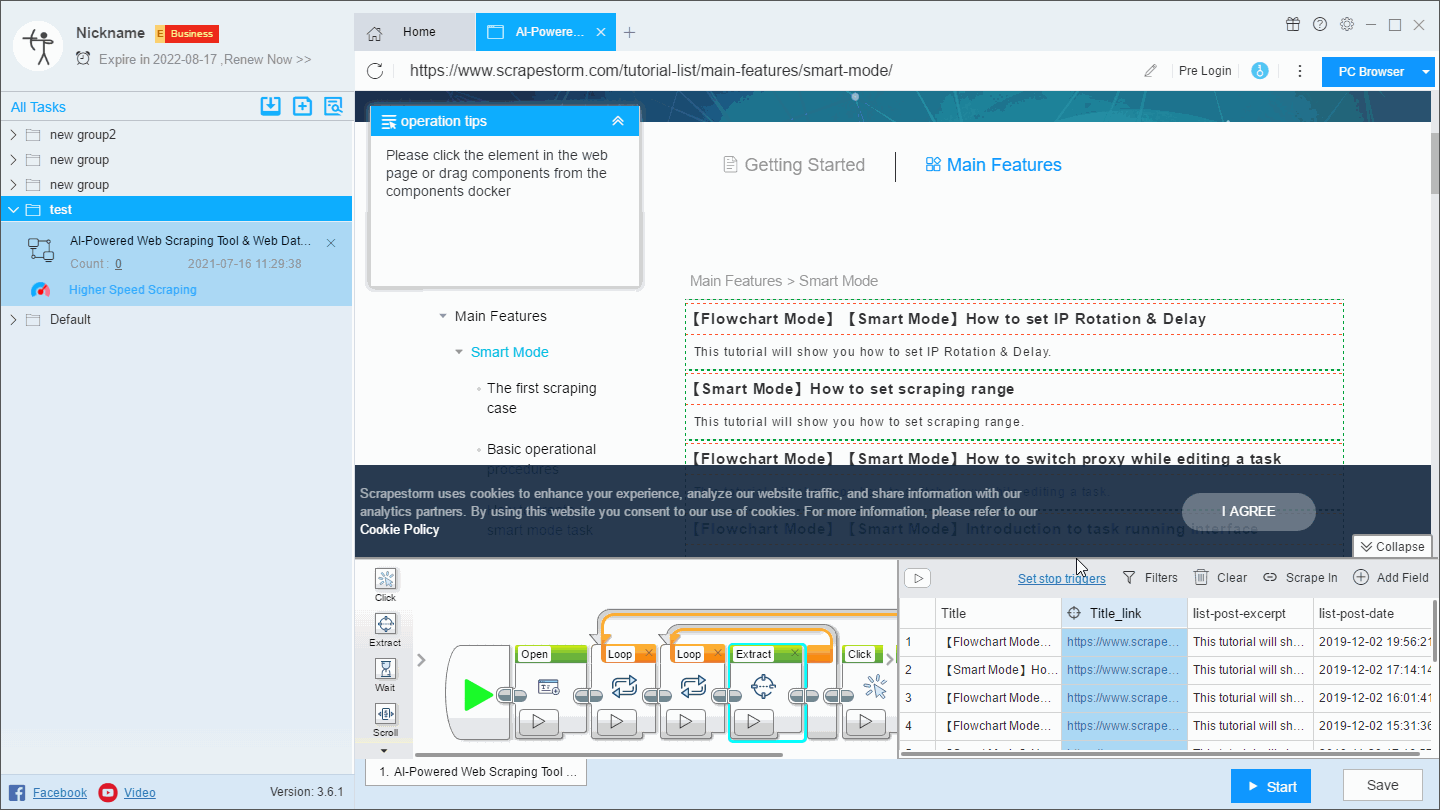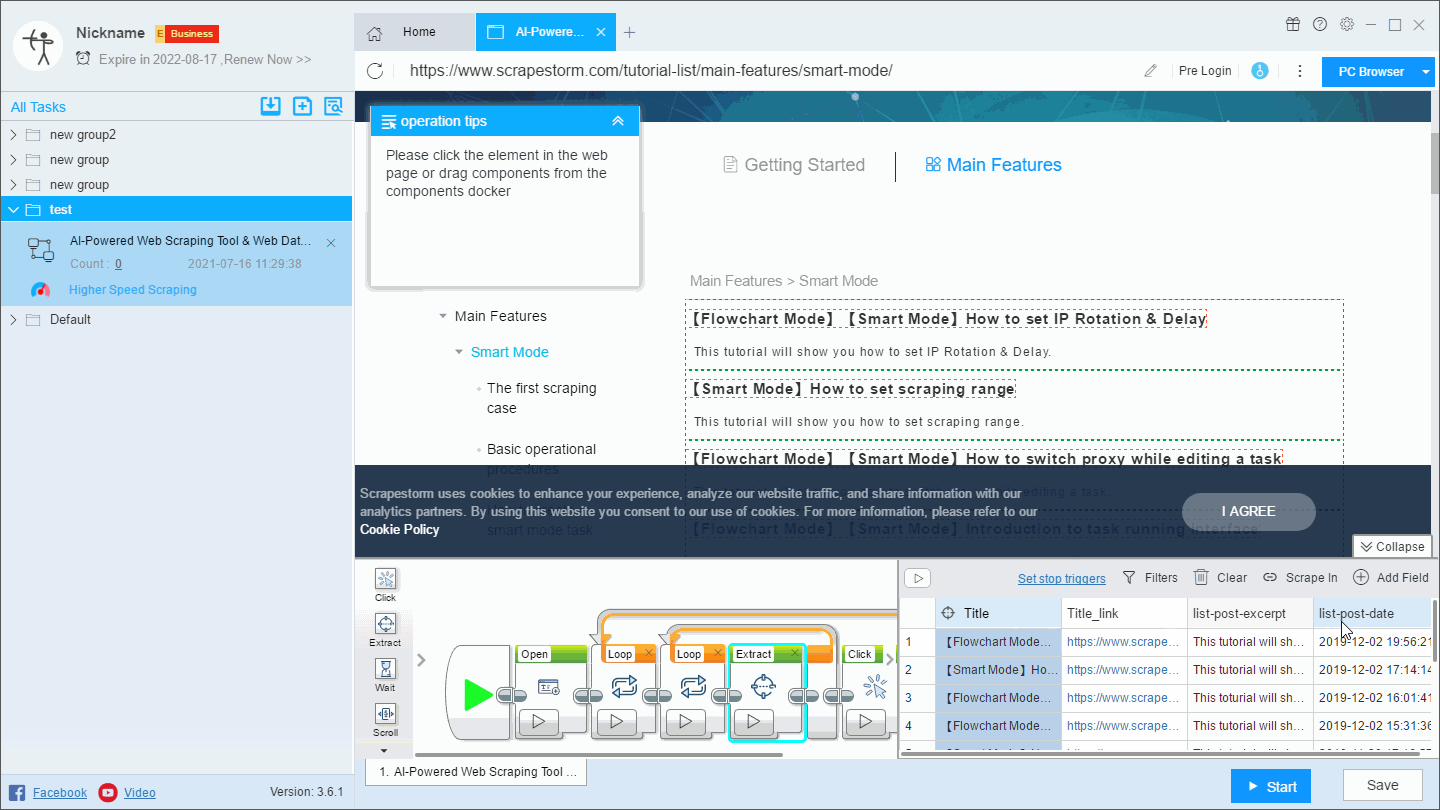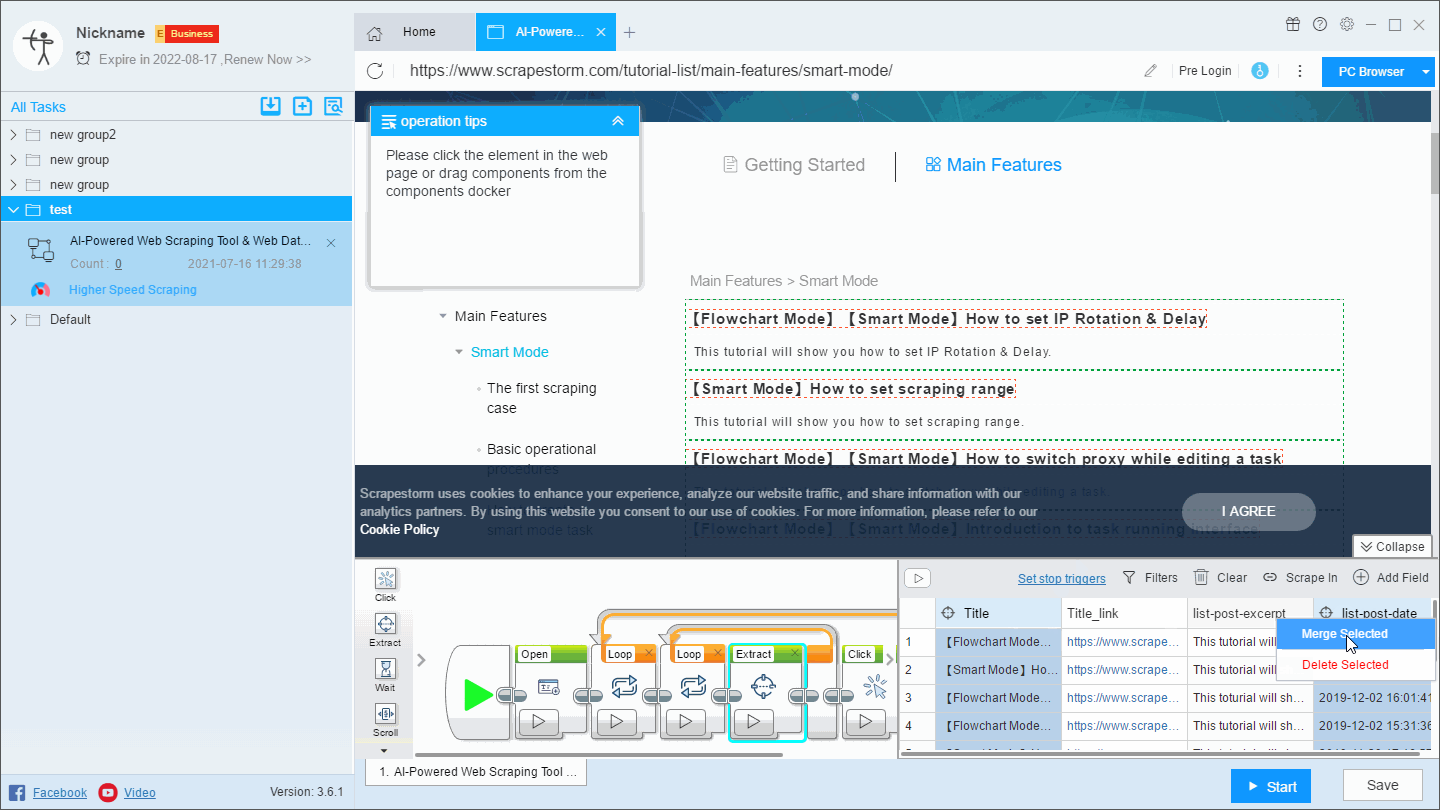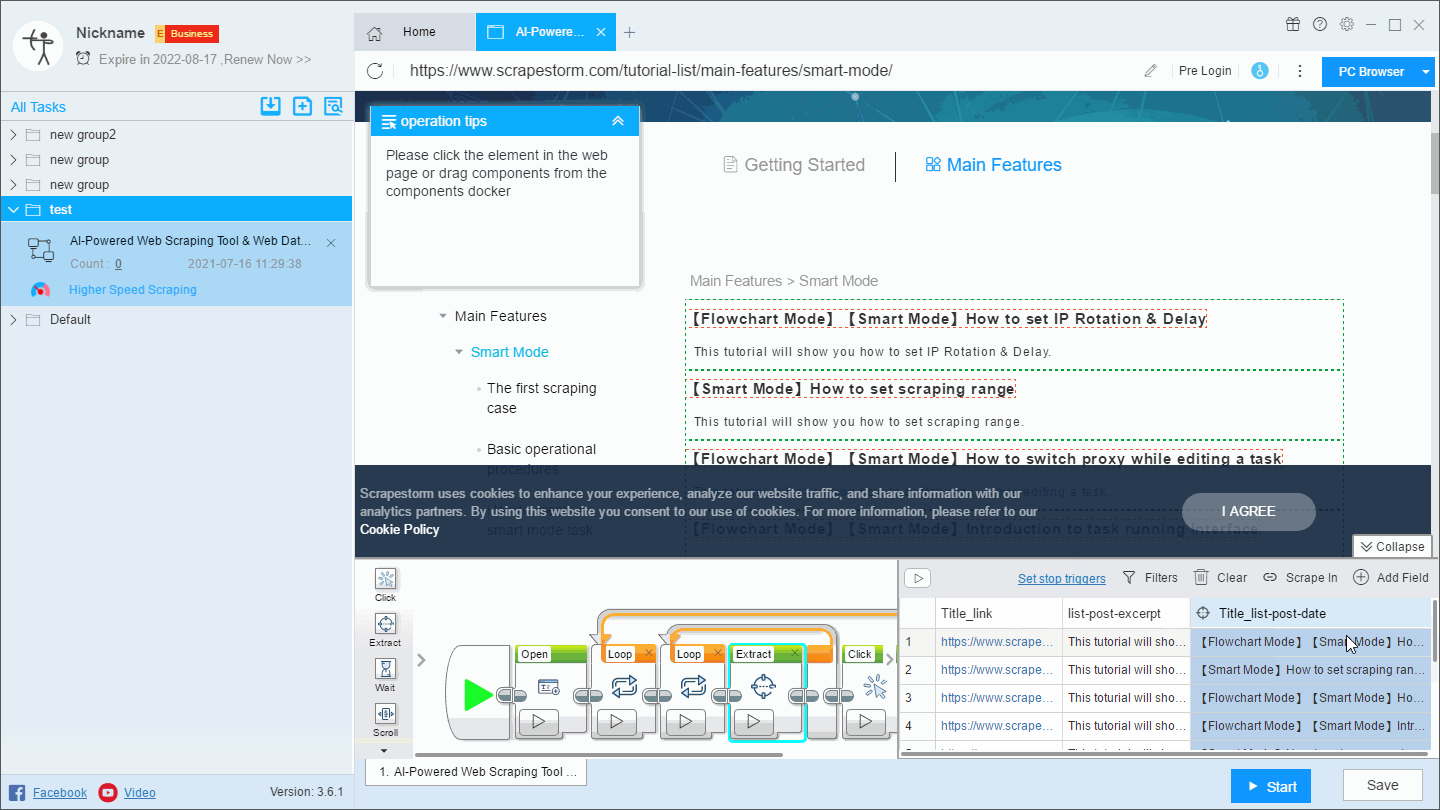
There are two ways to merge fields.
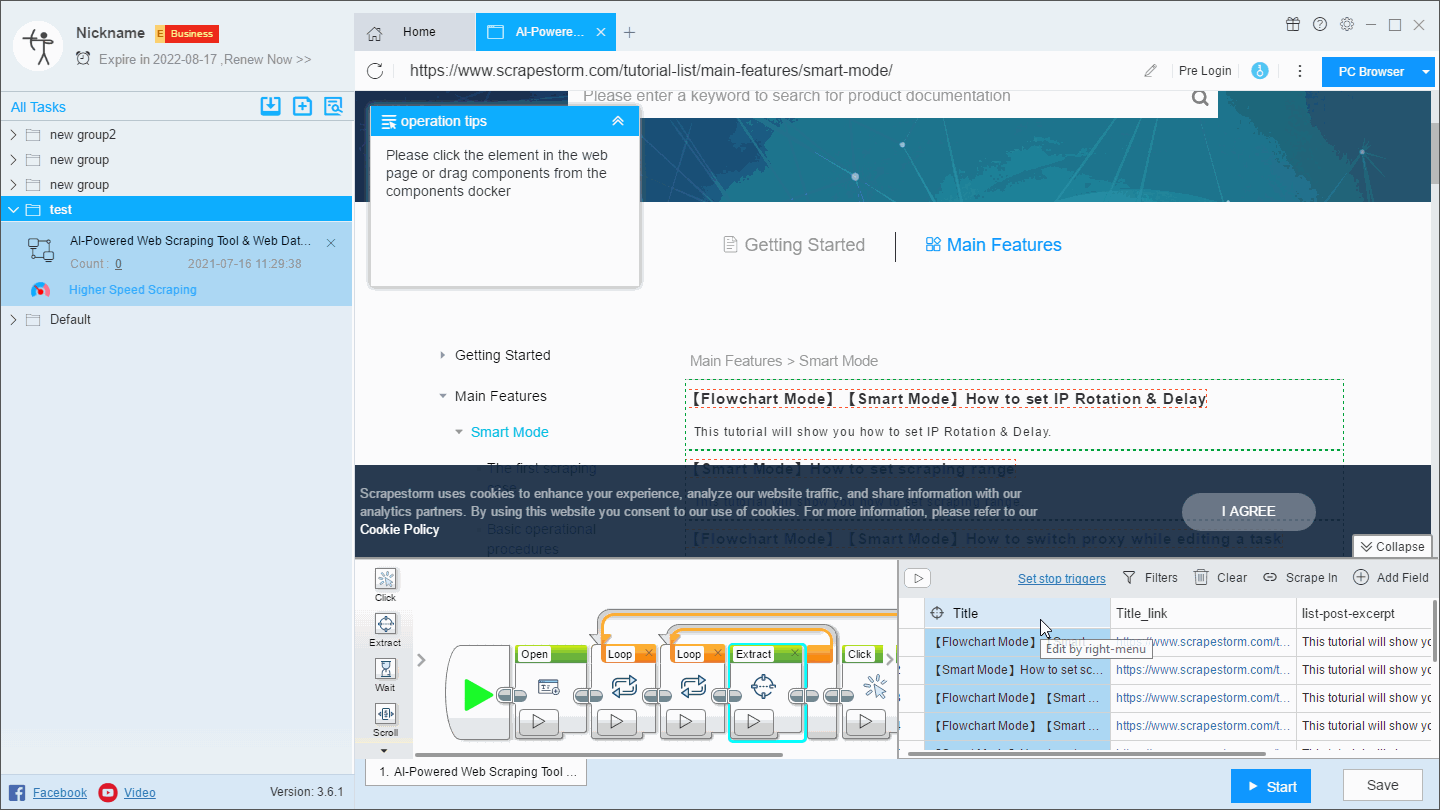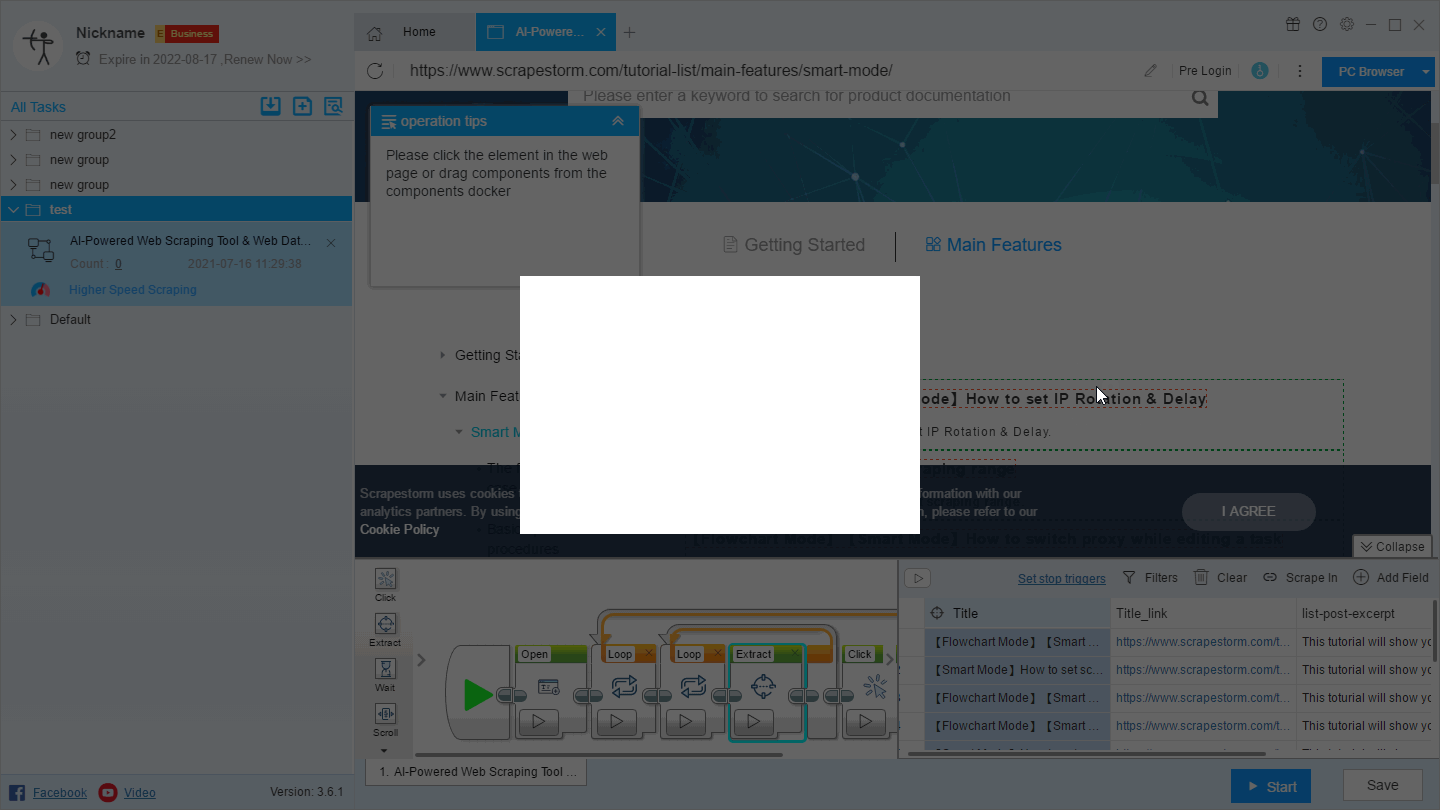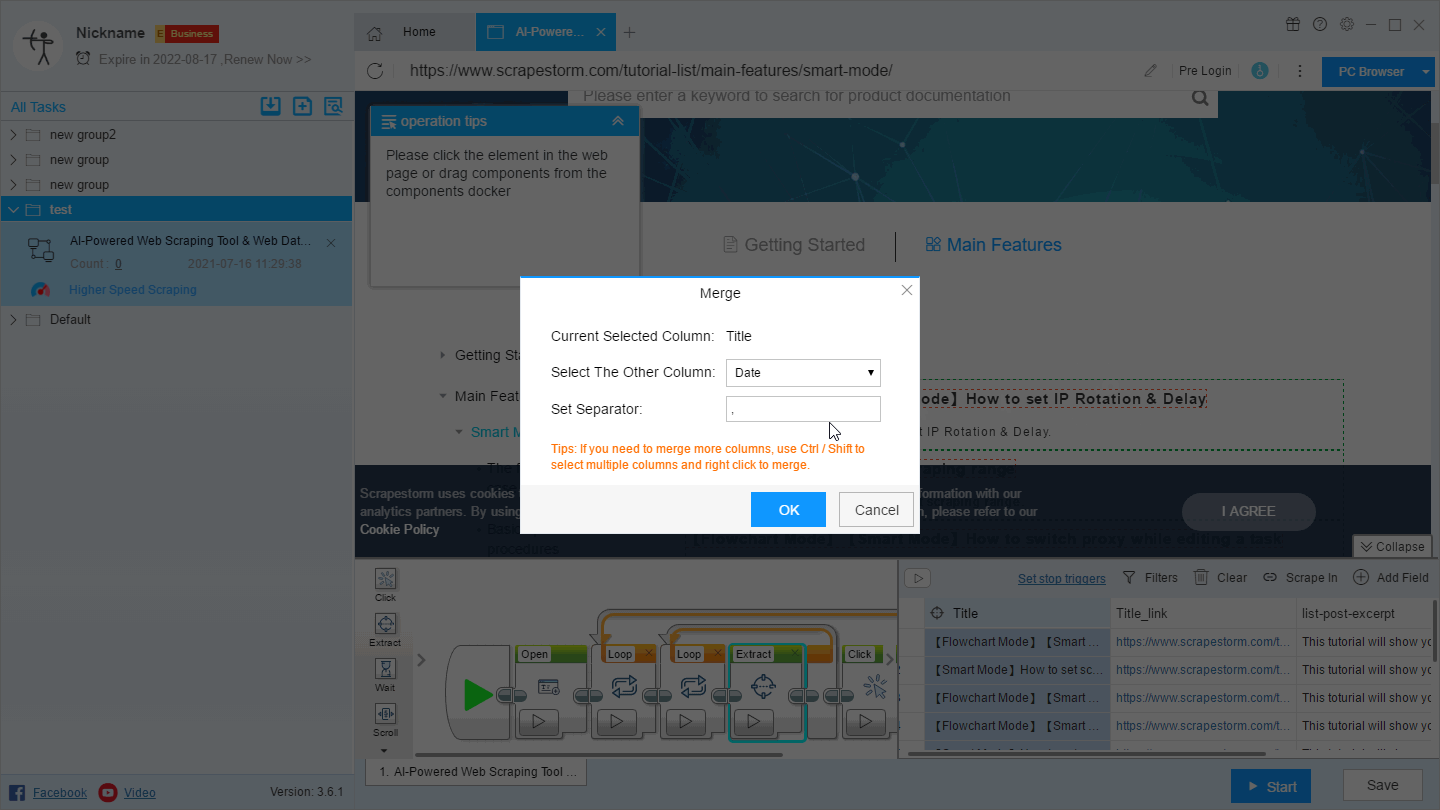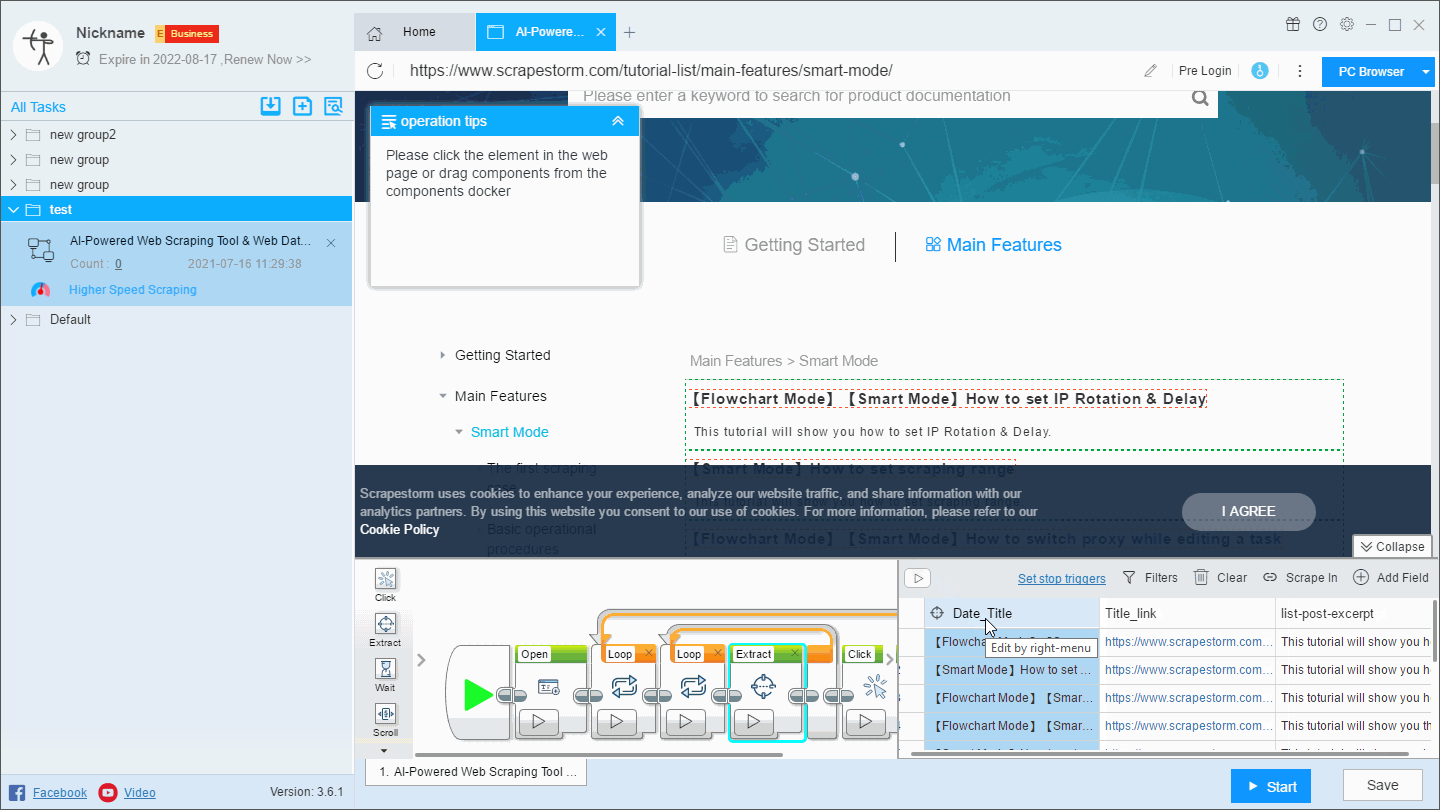
(1) Click on a field that needs to be merged, right click and select “Merge”, then select the fields you want to merge in the page, and select the appropriate separator, which is suitable for the combination of two fields.
(2) Press crtl or shift to select multiple fields, then right click on “Merge”. This method is suitable for the combination of multiple fields.
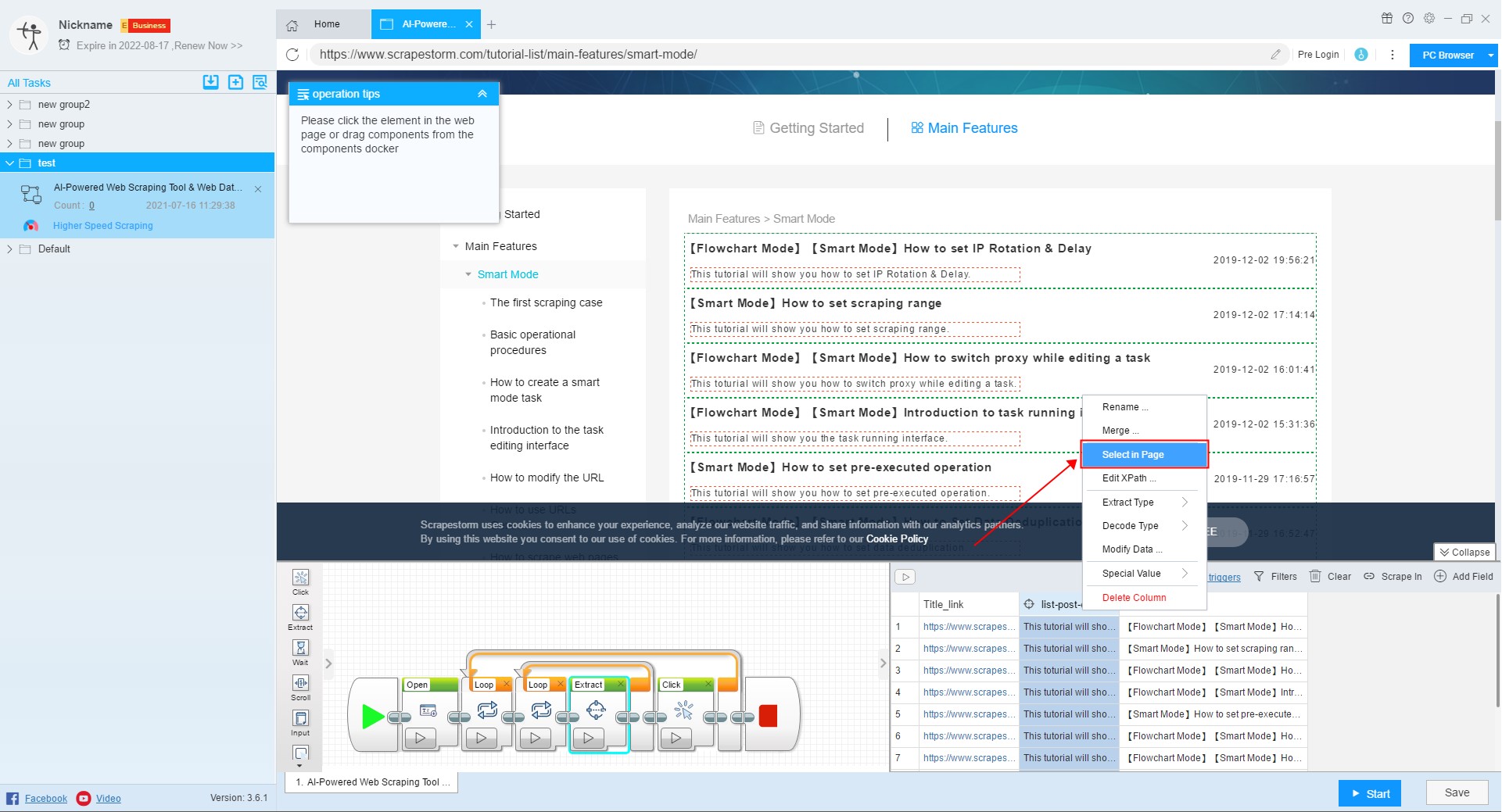
3. Select in page
If you want to modify the content extracted in the field, or add a new field to set the extraction content, you need to click “Select in page”, and then extract the required data in the web page.
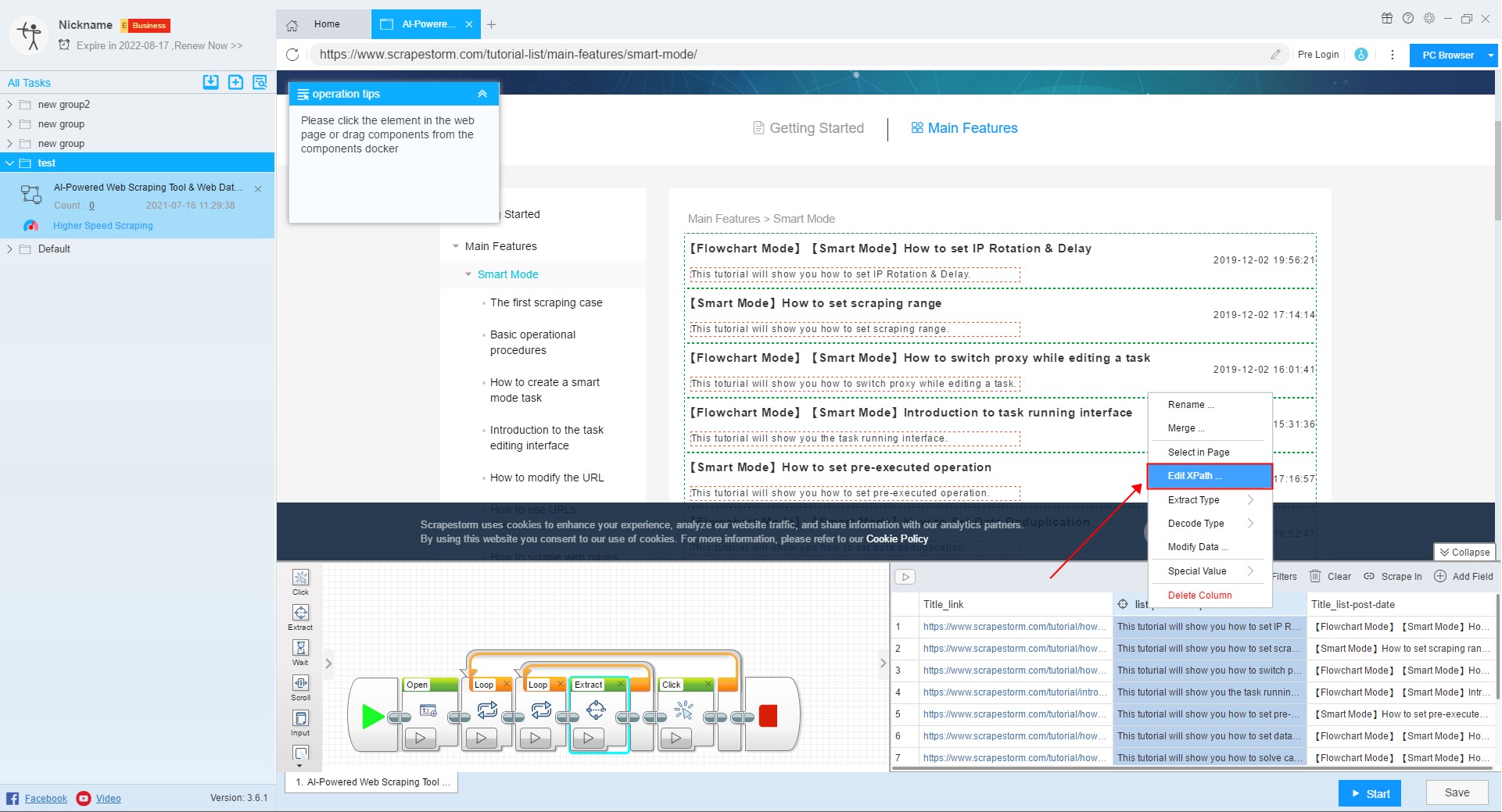
4. Edit Xpath
Xpath is a path query language that uses a path expression to find the location of the data we need in the web page. Users with a programming foundation can use this feature to set up a new XPath.
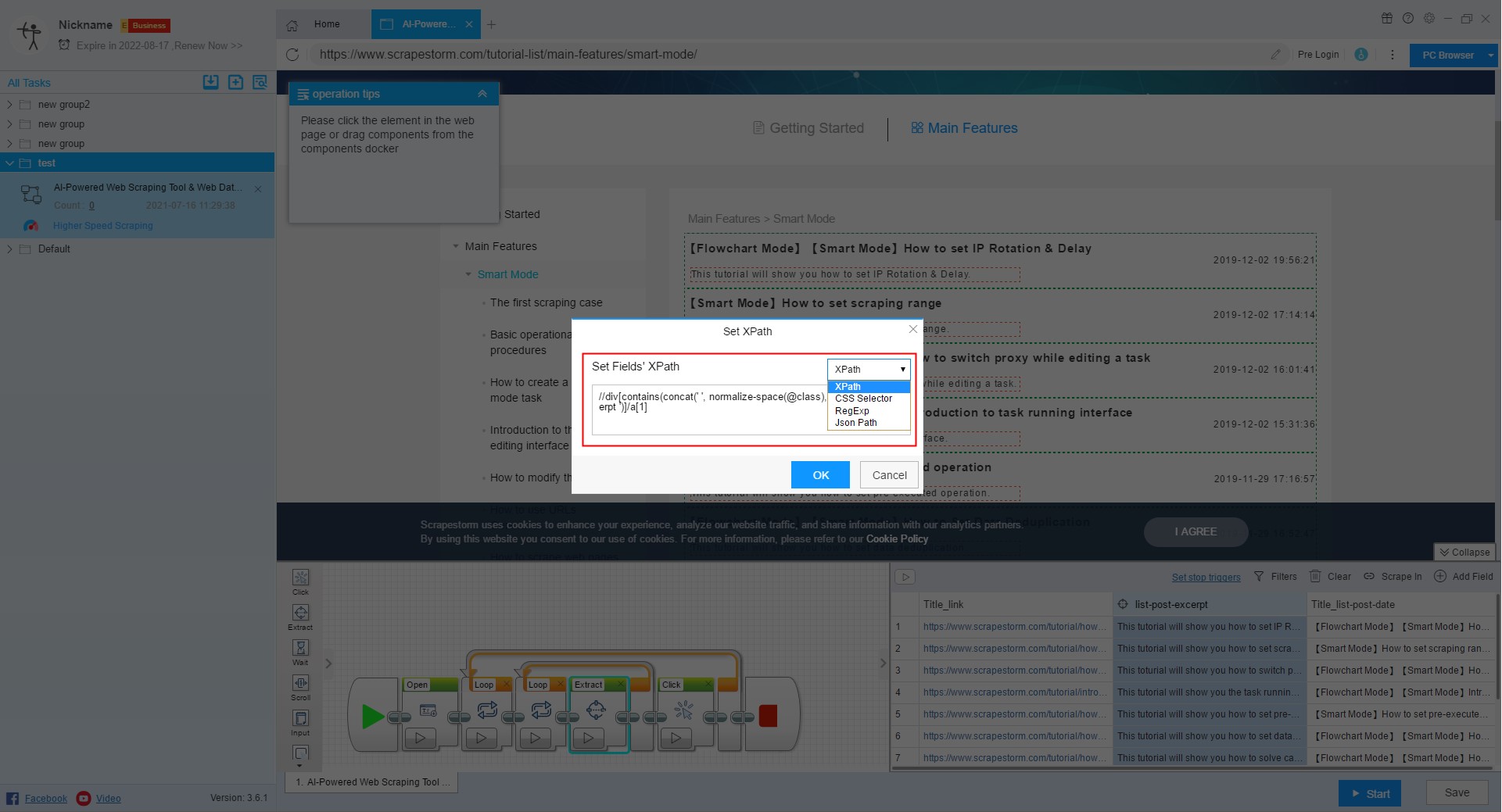
5. Extract Type
Different data needs to set different value attributes. When setting a new field, the value of the field defaults to a text field.
In general, when you select new data, ScrapeStorm will automatically help you determine the field attributes, you don’t need to set it up. However, if there is a judgment error, you can set the value attribute of the field yourself.
Text: Suitable for ordinary text data.
InnerHTML: Suitable for extracting HTML that does not include the content itself.
OuterHTML: Suitable for extracting HTML that includes the content itself.
Link URL: Suitable for extracting links.
Image/Video/Audio URL: Suitable for extracting images and other media.
Input Value: Suitable for extracting the text of input box, mostly used for keyword collection.
Download Button: Used to extract download address.
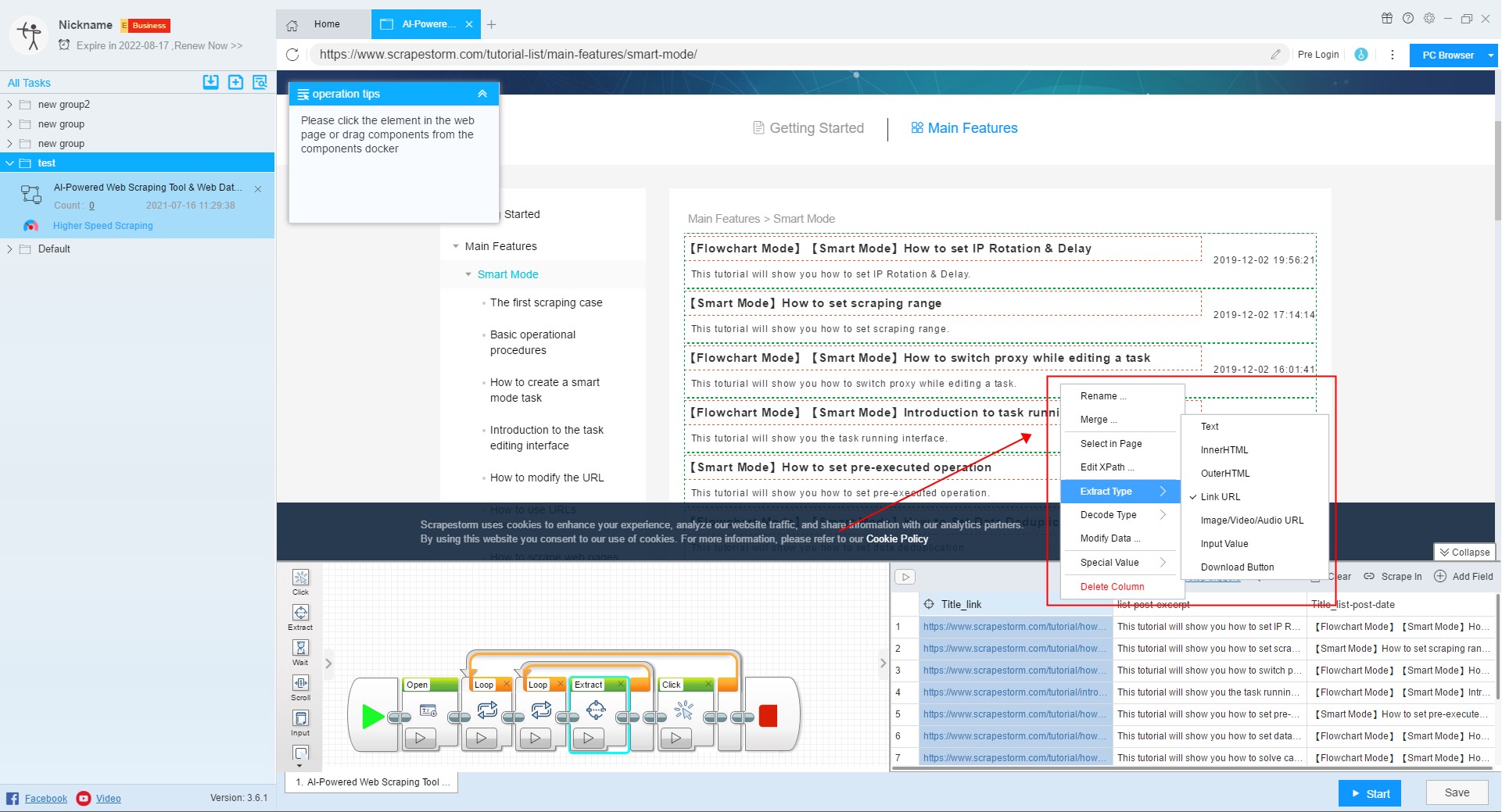
6. Decode Type
The software will automatically identify the fields to be decoded. In case that some fields are decoded incorrectly or not, you can manually select the decoding function. This is the function of Business Plan. Users need to upgrade to use it.
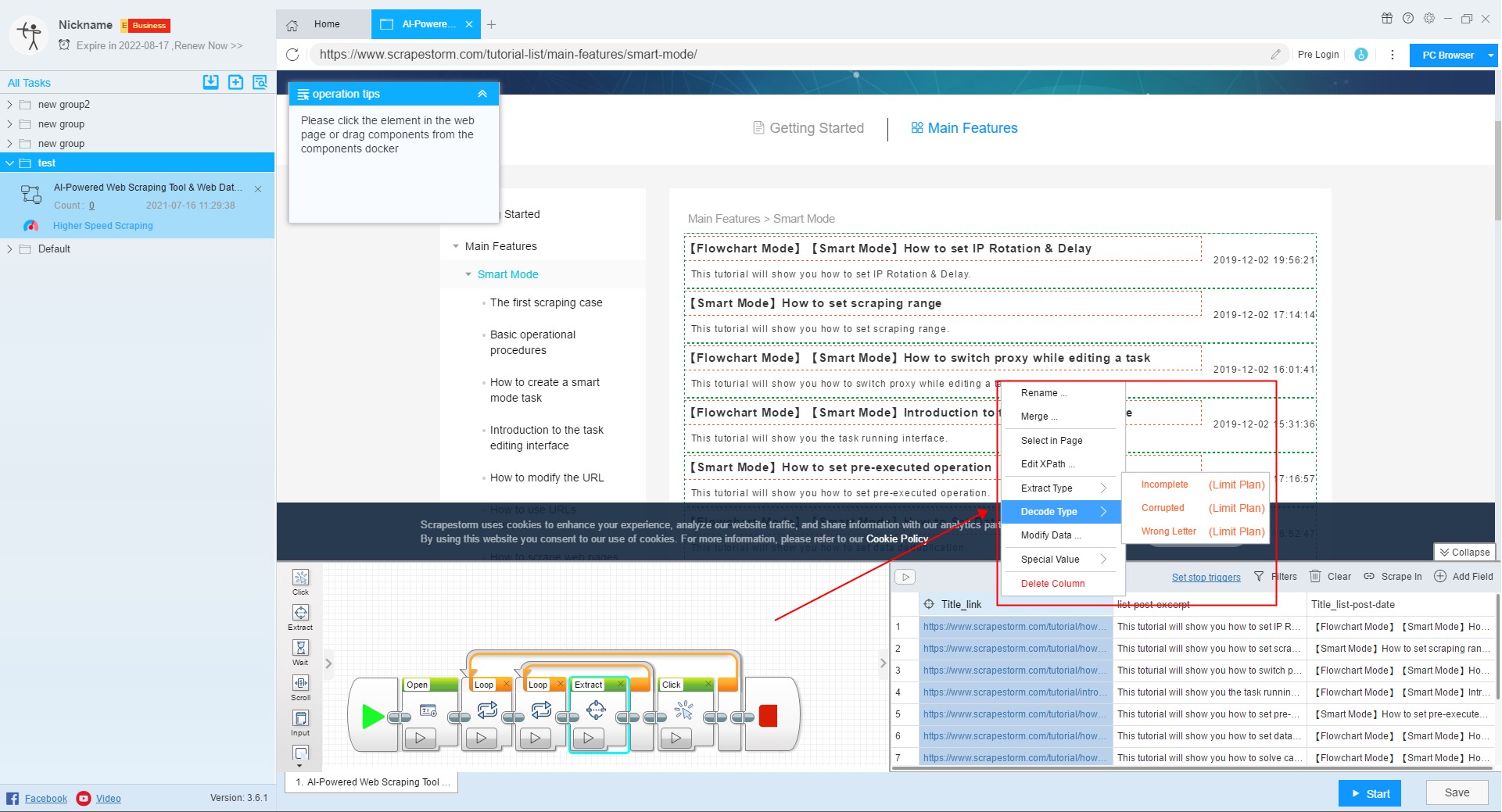
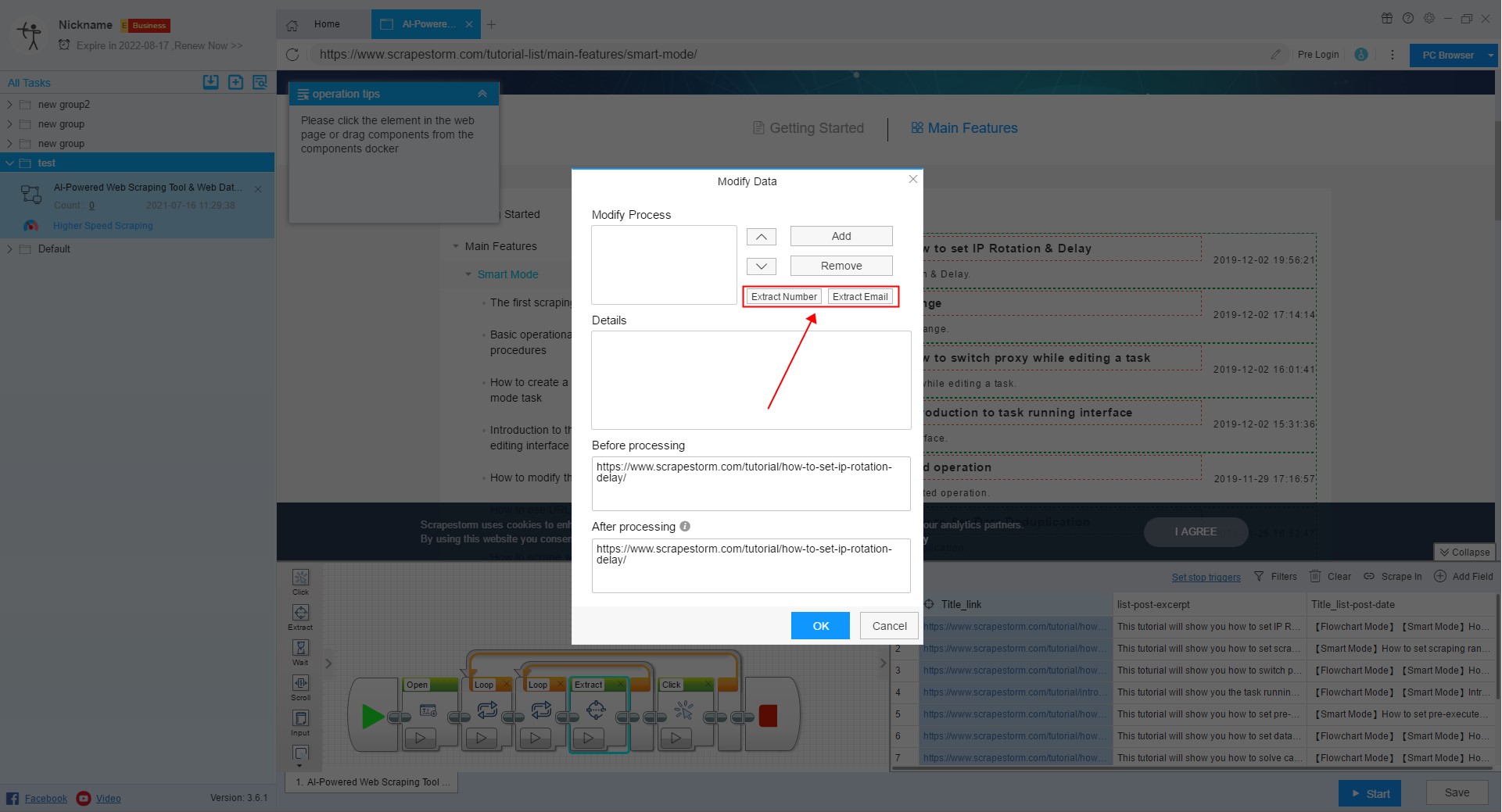
7. Modify data
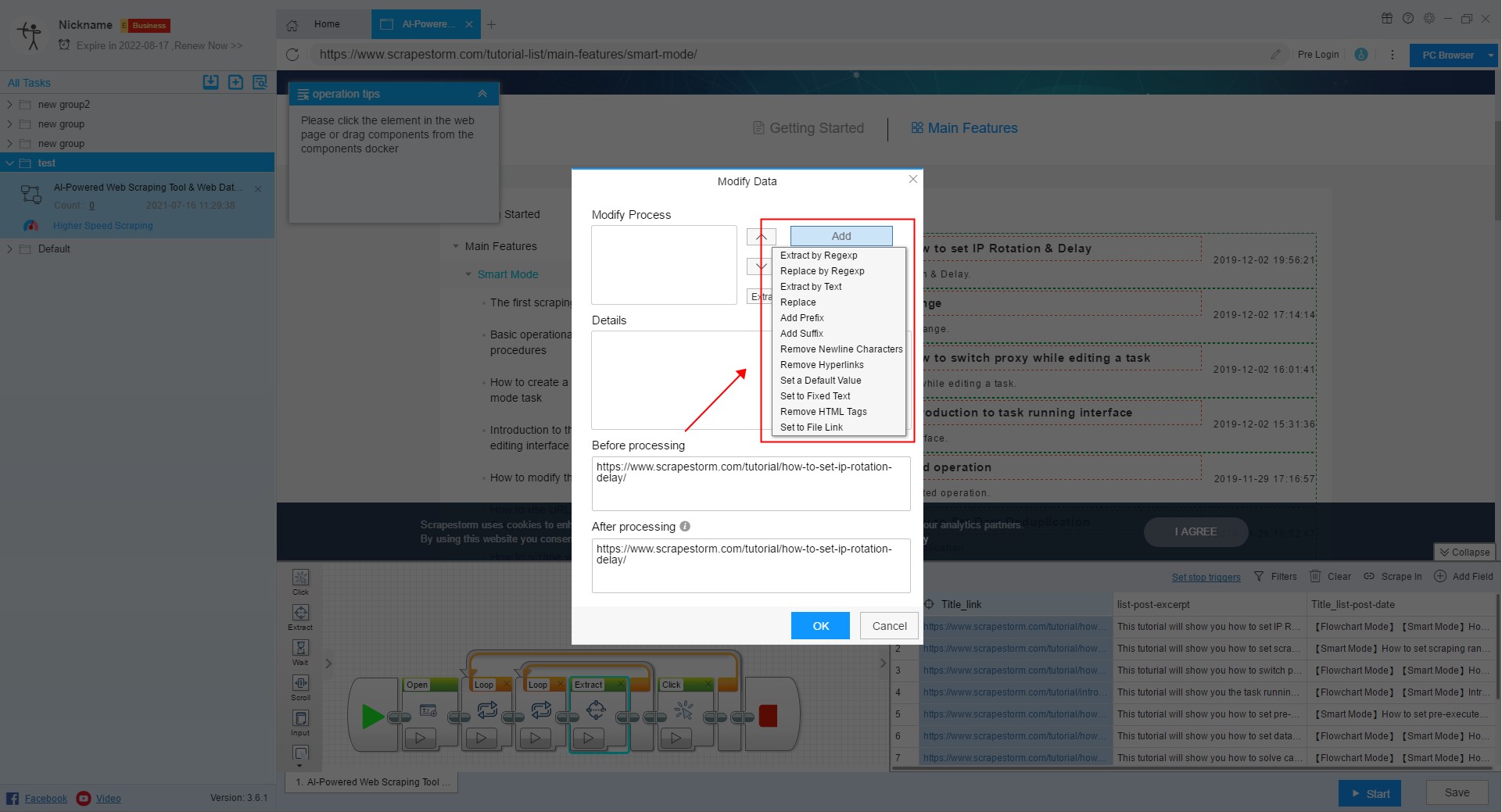
Sometimes we need to do some processing on the content of the extracted fields. For example, you only need the numbers and email in the fields, or replace the text in the fields with new text, or clear the blank characters at the beginning and the end, or create some new regular expressions. Alternatively, you can click on “Modify Data”.
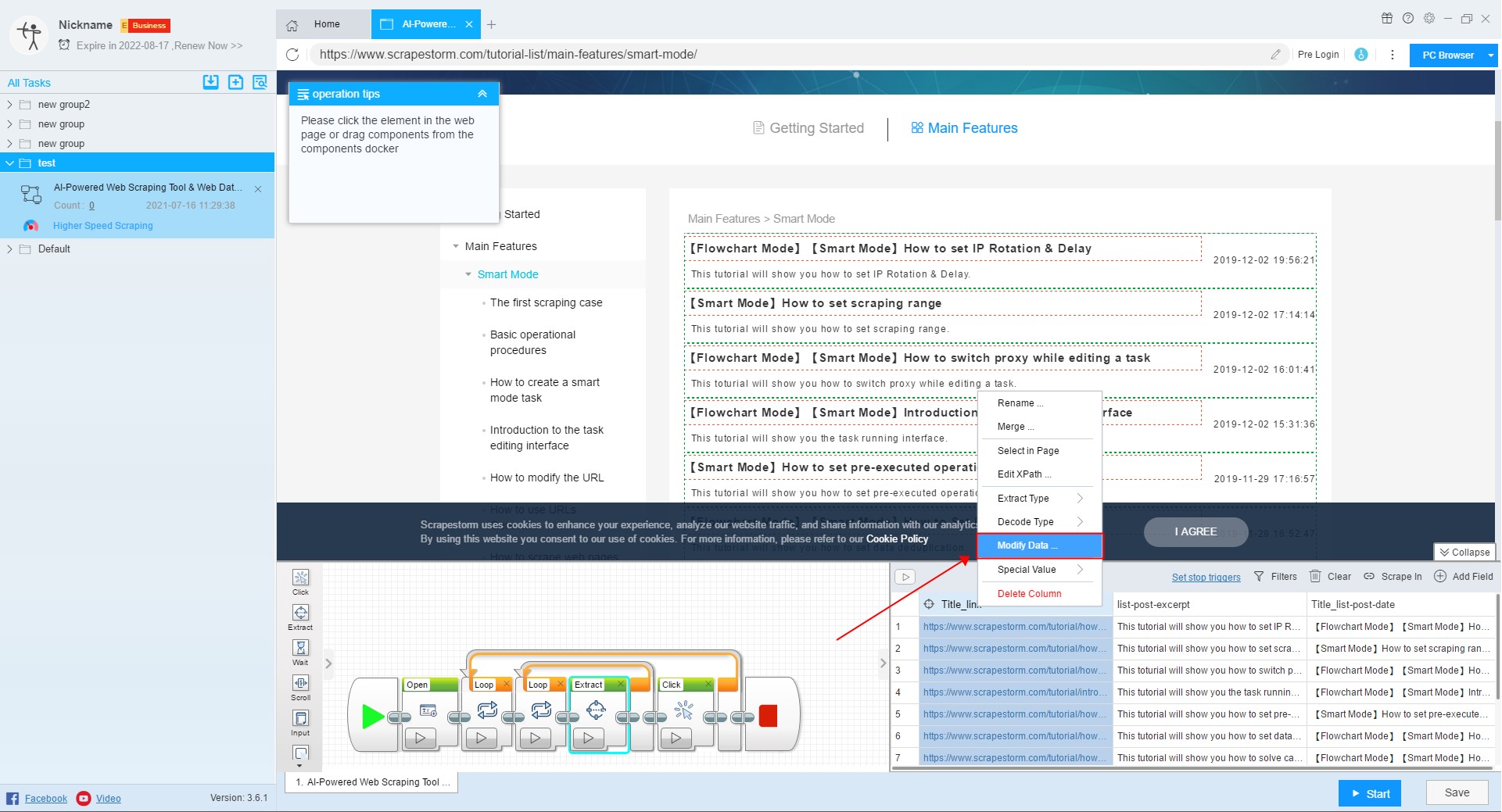
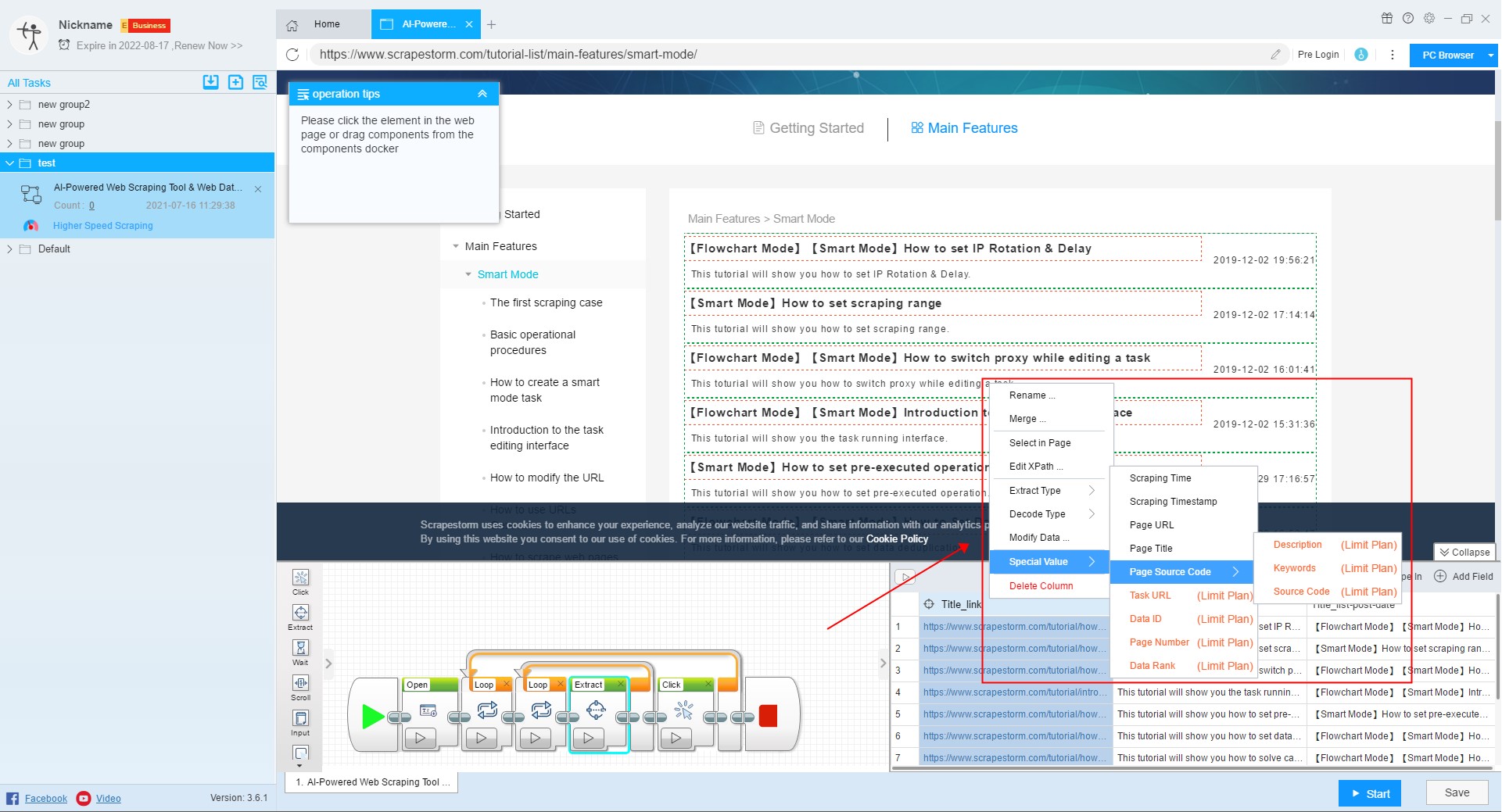
8. Special value
In the data scraping process, some users need to scrape some special fields, such as scraping time, page title, page URL, etc. These fields cannot be scraped directly in the web page, then you can use “Special Value” to set the field.
Users can create a new field, change the field to a special field, or change the original field to a special field.
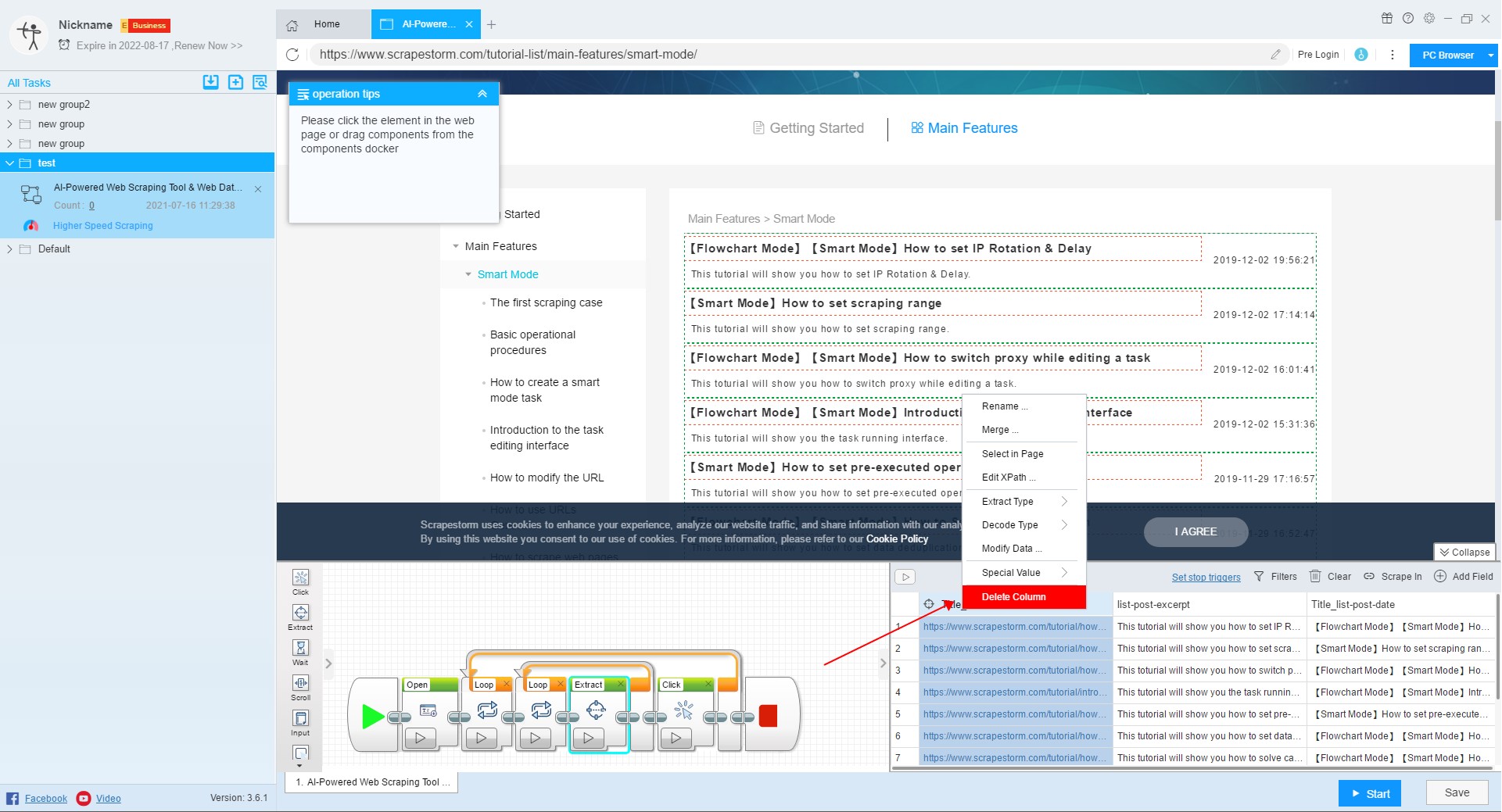
9. Delete column
You can right click on the field to select Delete, or press Ctrl or Shift to select multiple fields to delete.
10. Clear
If the user does not need the fields that the system automatically recognizes, you can click “Clear” to clear the fields and you can reset the required fields.
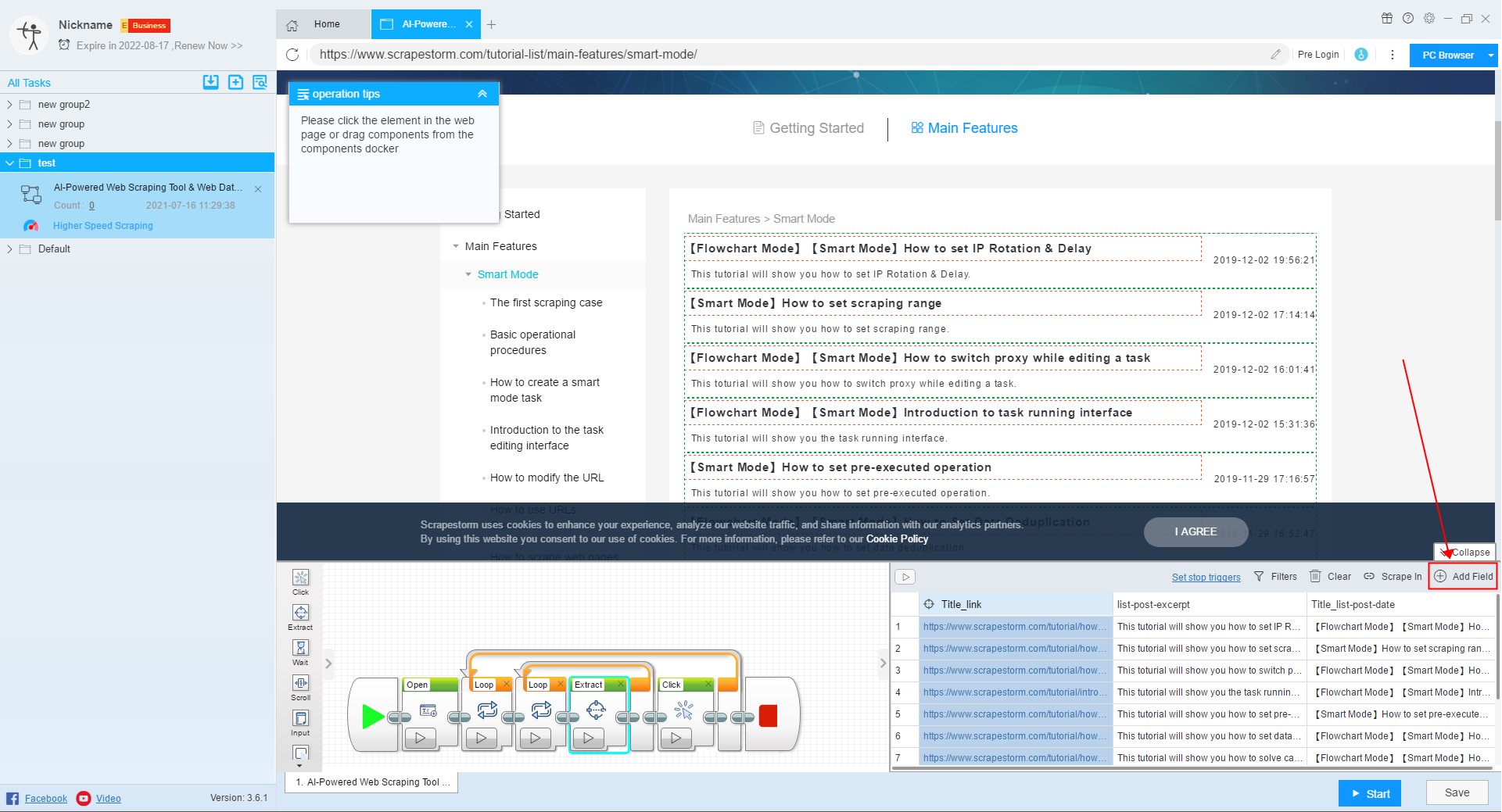
11. Add field
If you want to add a new field, click on “Add Field” in the upper right corner, right click on the newly added field, click on “Select in Page”, and extract the required data from the page.