Web crawler
Web crawler, also known as a web crawler or web spider, is an automated program or script designed to browse the Internet to collect information, data or perform specific tasks.
2023-10-26 20:10:40
Web crawler, also known as a web crawler or web spider, is an automated program or script designed to browse the Internet to collect information, data or perform specific tasks.
2023-10-26 20:10:40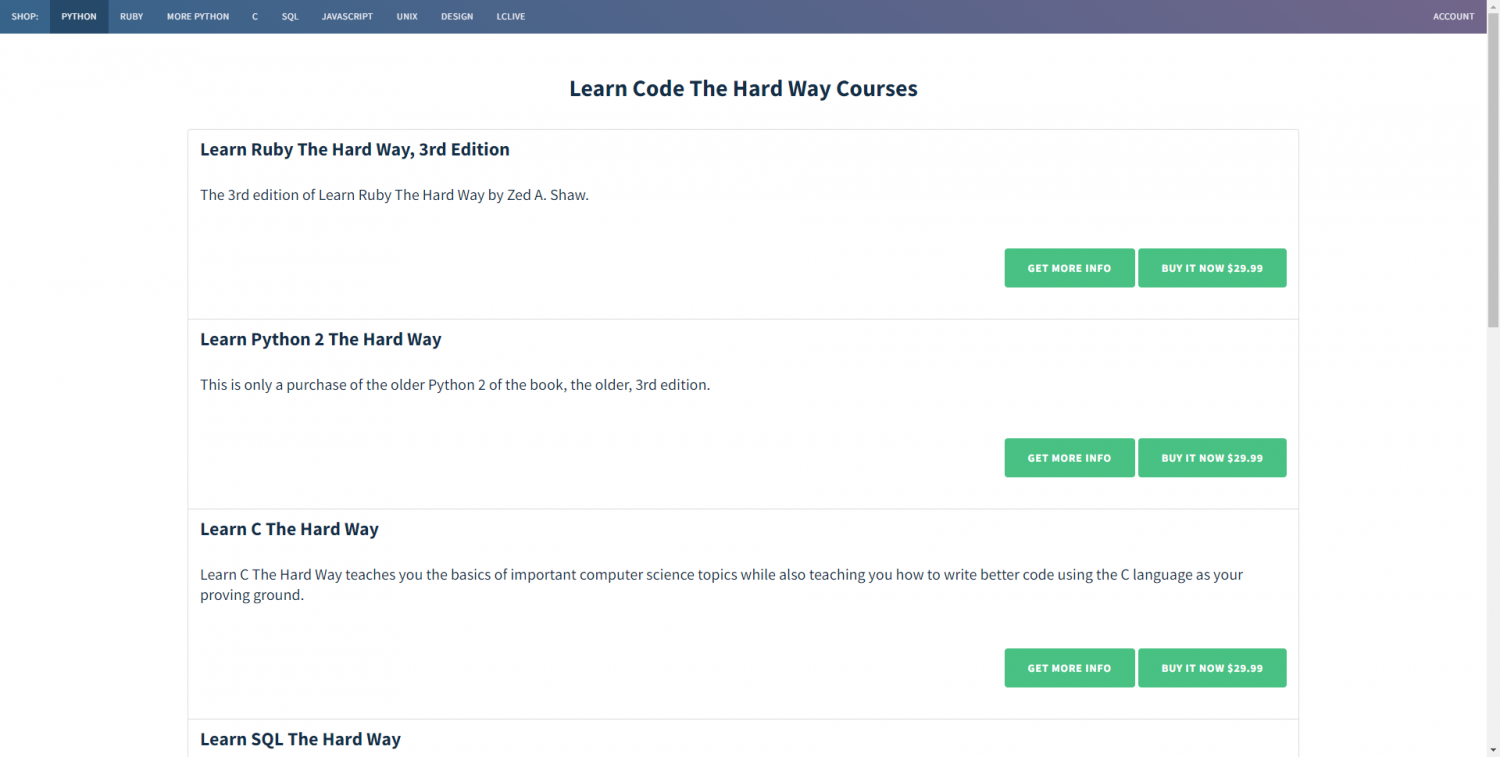
This article will introduce 5 python self-study websites.
2022-11-11 13:24:55
Here are 5 practical Python scripts covering file operations, automation, and web requests, with clear explanations and ready-to-use code:
2025-03-27 17:21:34
This article will introduce basic knowledge of Python.
2021-10-29 16:24:18
This article will introduce the advantages and disadvantages of Python.
2021-11-12 15:33:54
In the future, more and more libraries will use Python as the front end (improving programming efficiency) and Rust as the back end (improving performance).
2024-02-29 13:08:21
Crawl rate refers to the time interval or frequency at which a web crawler or crawler program retrieves data from a target website.
2023-11-17 16:14:46
Deep Crawling refers to a technical method in which a web crawler not only collects information from the homepage or surface pages of a target website but also recursively follows links within pages to continuously access and collect data from deeper levels of the site. Unlike shallow crawling, which only captures surface-level pages, deep crawling can penetrate a website's directory structure, pagination navigation, category links, and dynamically loaded content, thereby obtaining more comprehensive and complete data resources. This technique typically requires the integration of link deduplication, crawling strategy optimization, anti-scraping mechanism handling, and distributed scheduling to efficiently and stably complete large-scale data collection tasks.
2026-03-23 07:05:00
Xinhuanet is the official news portal operated by Xinhua News Agency, the state-run news agency of the People's Republic of China.
2025-09-28 10:13:52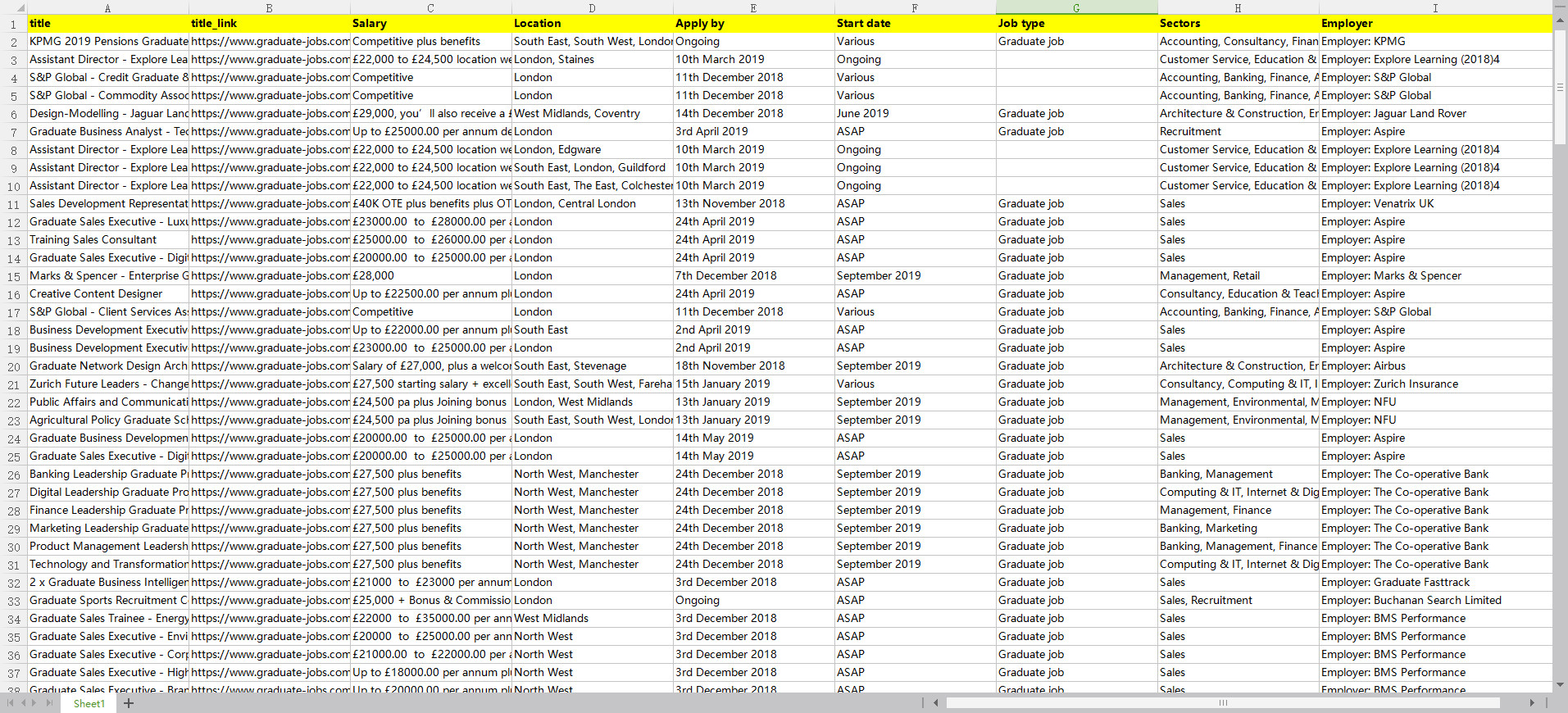
This tutorial will show you how to scrape jobs from graduate-jobs.com with ScrapeStorm. No Programming Needed. Visual Operation.
2018-11-13 15:18:55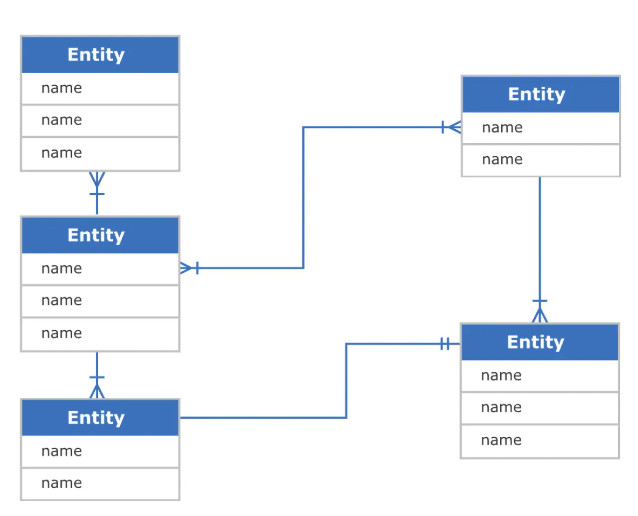
Data entity is an information unit in a data model that has independent existence, uniqueness, and specific attributes.
2025-06-24 19:34:21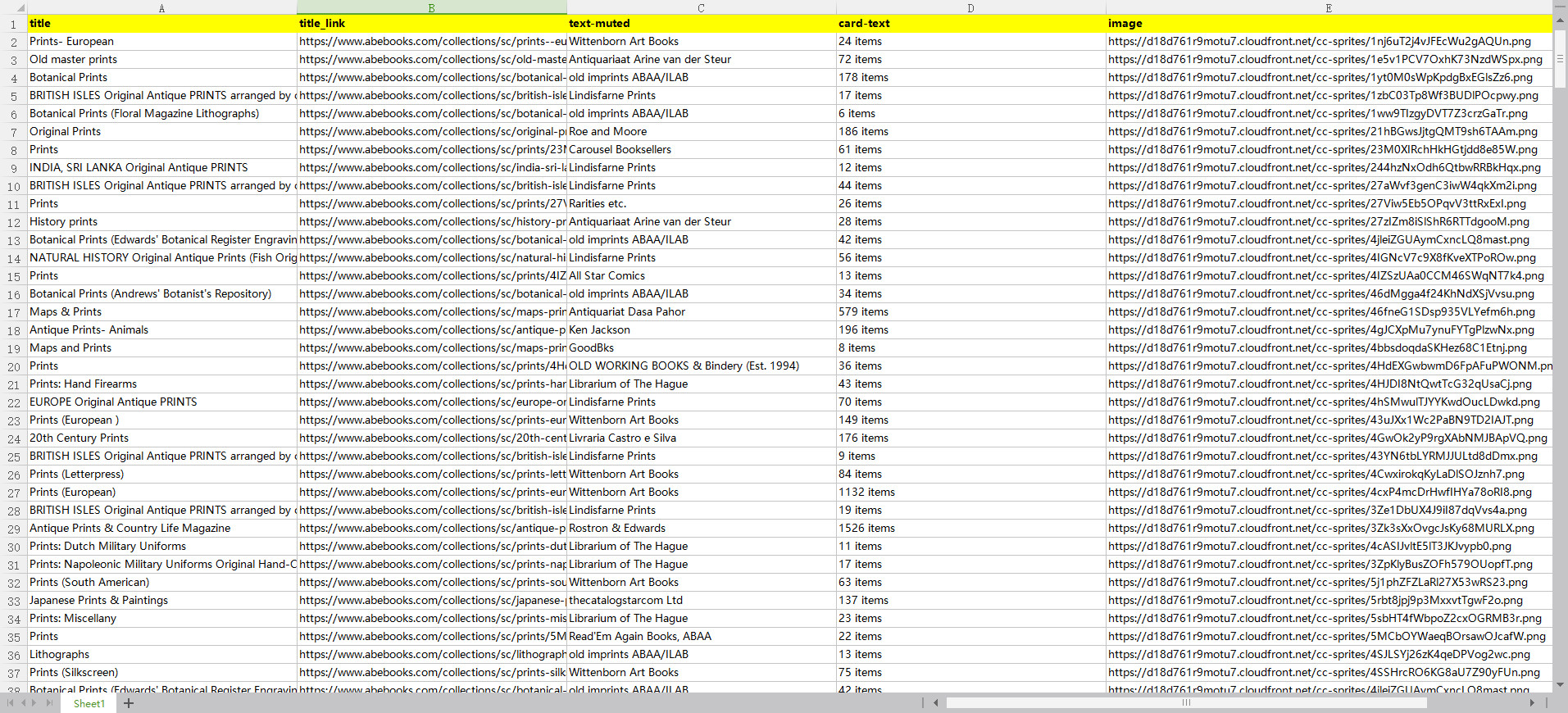
This tutorial will show you how to scrape information from AbeBooks with ScrapeStorm. No Programming Needed. Visual Operation.
2018-11-19 17:25:51