AI-Powered Visual Web Scraping Tool
Built by ex-Google crawler team. No Programming Needed. Visual Operation. Easy to Use.
Intelligent identification of data, no manual operation required
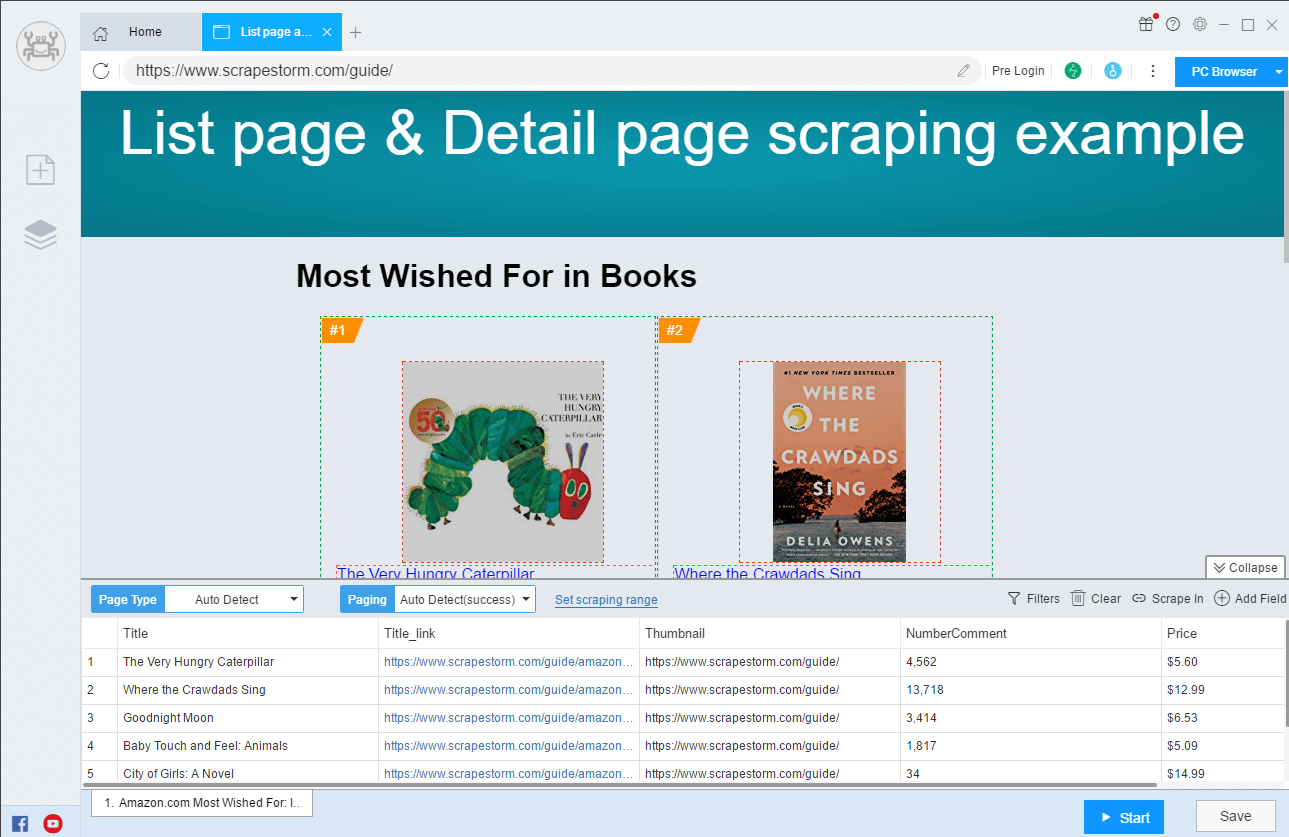
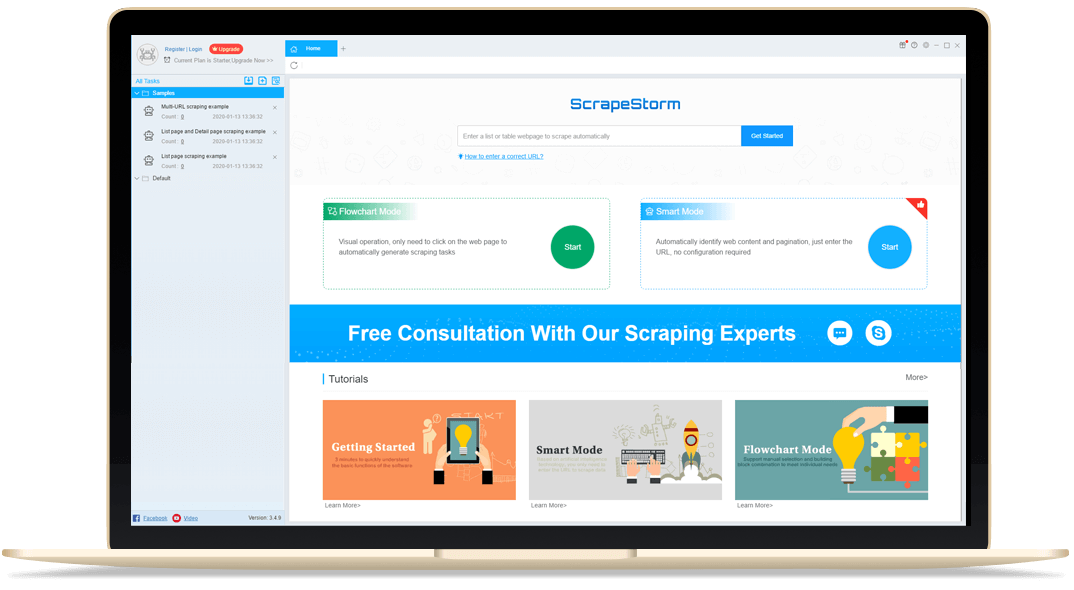
Smart Mode: Based on artificial intelligence algorithms, ScrapeStorm intelligently identifies List Data, Tabular Data and Pagination Buttons without having to manually set rules, just enter the URLs.
Visual click operation, Easy to use
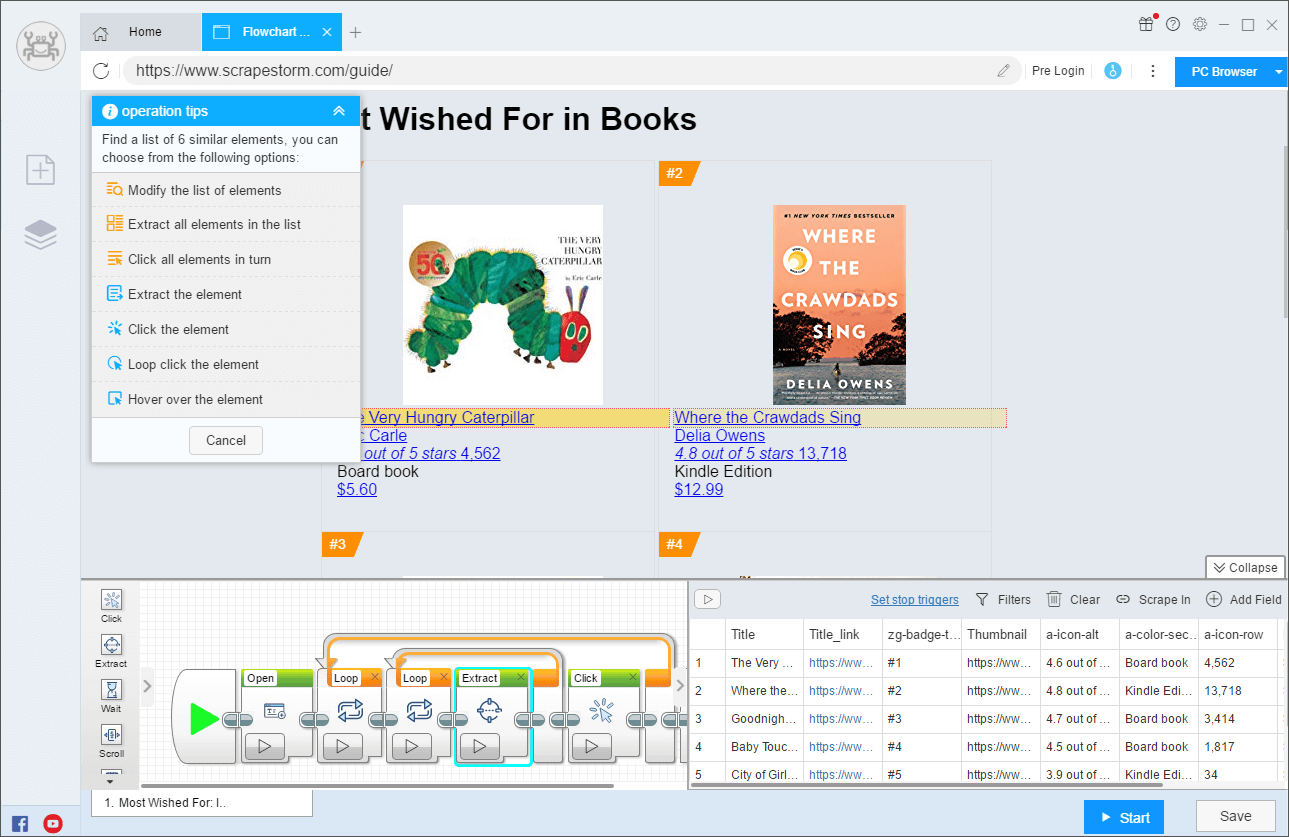
Flowchart Mode: Just click on the webpage according to the software prompts, which is completely in line with the way of manually browsing the webpage.
It can generate complex scraping rules in a few simple steps, and the data of any webpage can be easily scrapered.
Simulation Operations: input text, click, move mouse, drop-down box, scroll page, wait for loading, loop operation, and evaluate conditions.
Multiple data export methods
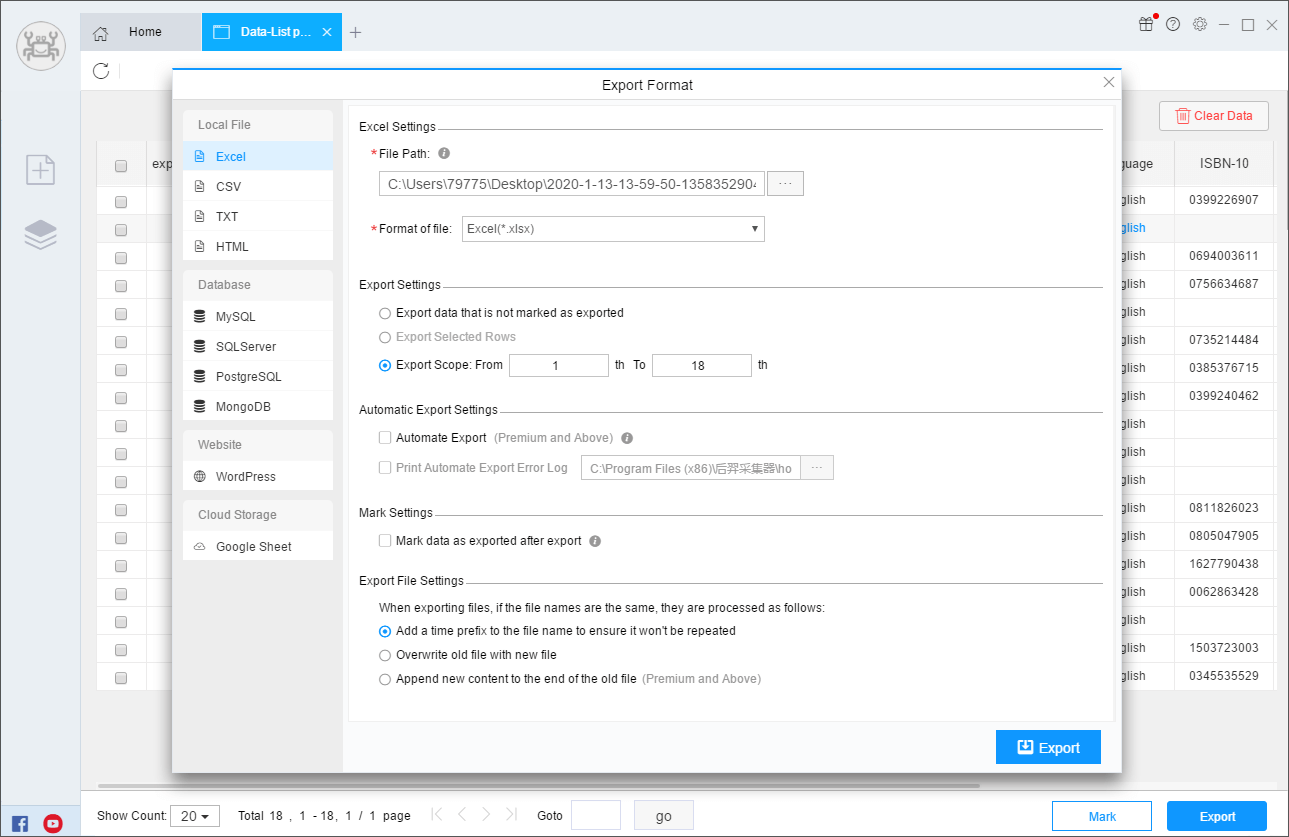
The scrapered data can be exported to a local file or a cloud server. Support types include Excel, CSV, TXT, HTML, MySQL, MongoDB, SQL Server, PostgreSQL, WordPress, and Google Sheets.
Powerful, providing Enterprise Scraping Services
ScrapeStorm has powerful scraping capabilities, high scraping efficiency and professional services to meet the scraping needs of individuals, teams and enterprises.
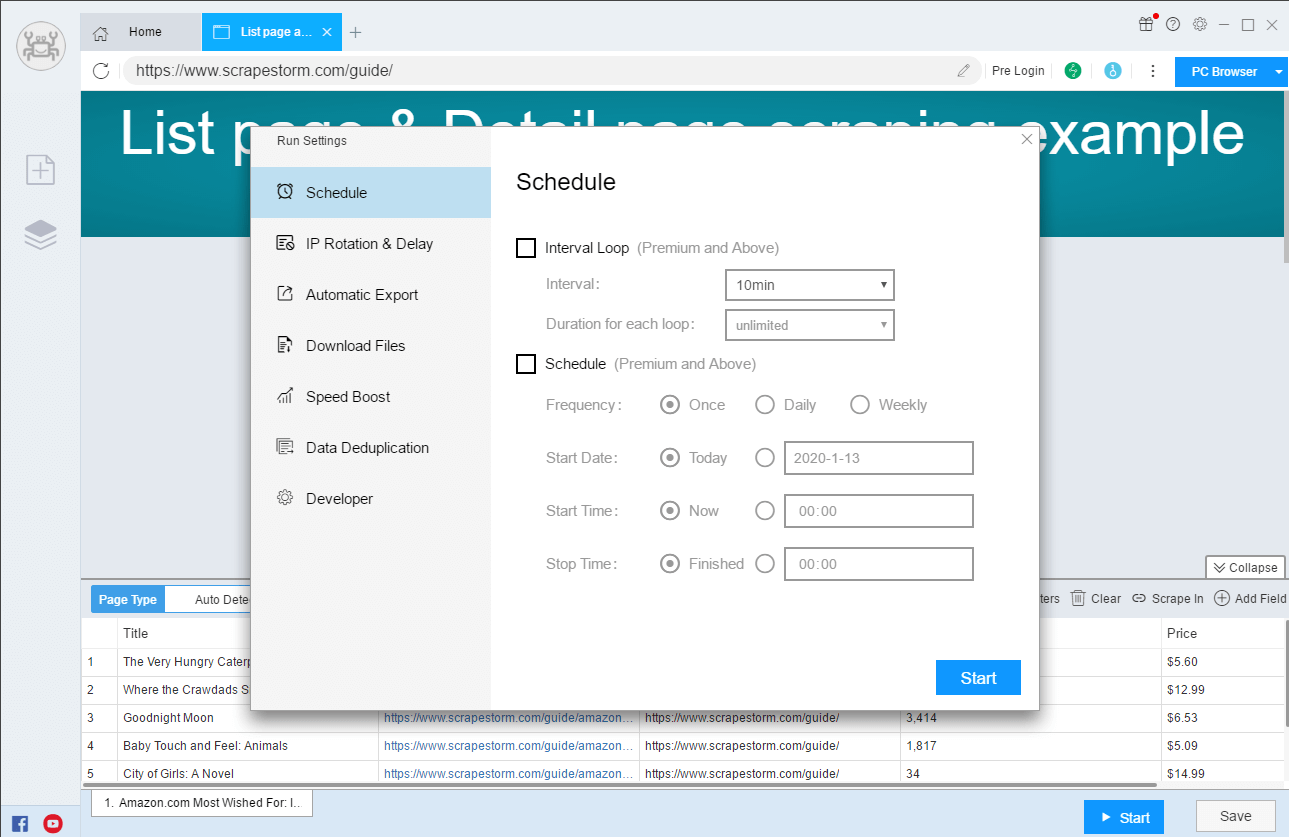
Powerful Features: Schedule, IP Rotation, Automatic Export, File Download, Speed Boost Engine, Start and Export by Group, Webhook, RESTful API, SKU Scraper, etc.
Cloud account, Convenient and Fast
By registering an account, all your scraping tasks will be automatically saved to the cloud server, so you don't have to worry about the loss of the scraping tasks.
Unlimited computers, you can log in to your ScrapeStorm account and use the software on any computer, and the scraping tasks will be updated synchronously.
All systems supported, leading technology
Support for Windows, Mac and Linux operating systems, all versions of the same. Switching platforms is very convenient.
Web Data Scraping is Easier than You Think
关闭