【Smart Mode】【Flowchart Mode】How to use RESTful API | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial will show you how to use API. ScrapeStormFree Download
By using ScrapeStorm‘s RESTful API, you can control the scraping task by sending an HTTP request.
Features that can be supported include: Fetch the tasks list, Start a task, Stop a task, Get status of a task, Delete a task, etc.
This function can be set up in the settings center, as shown below:
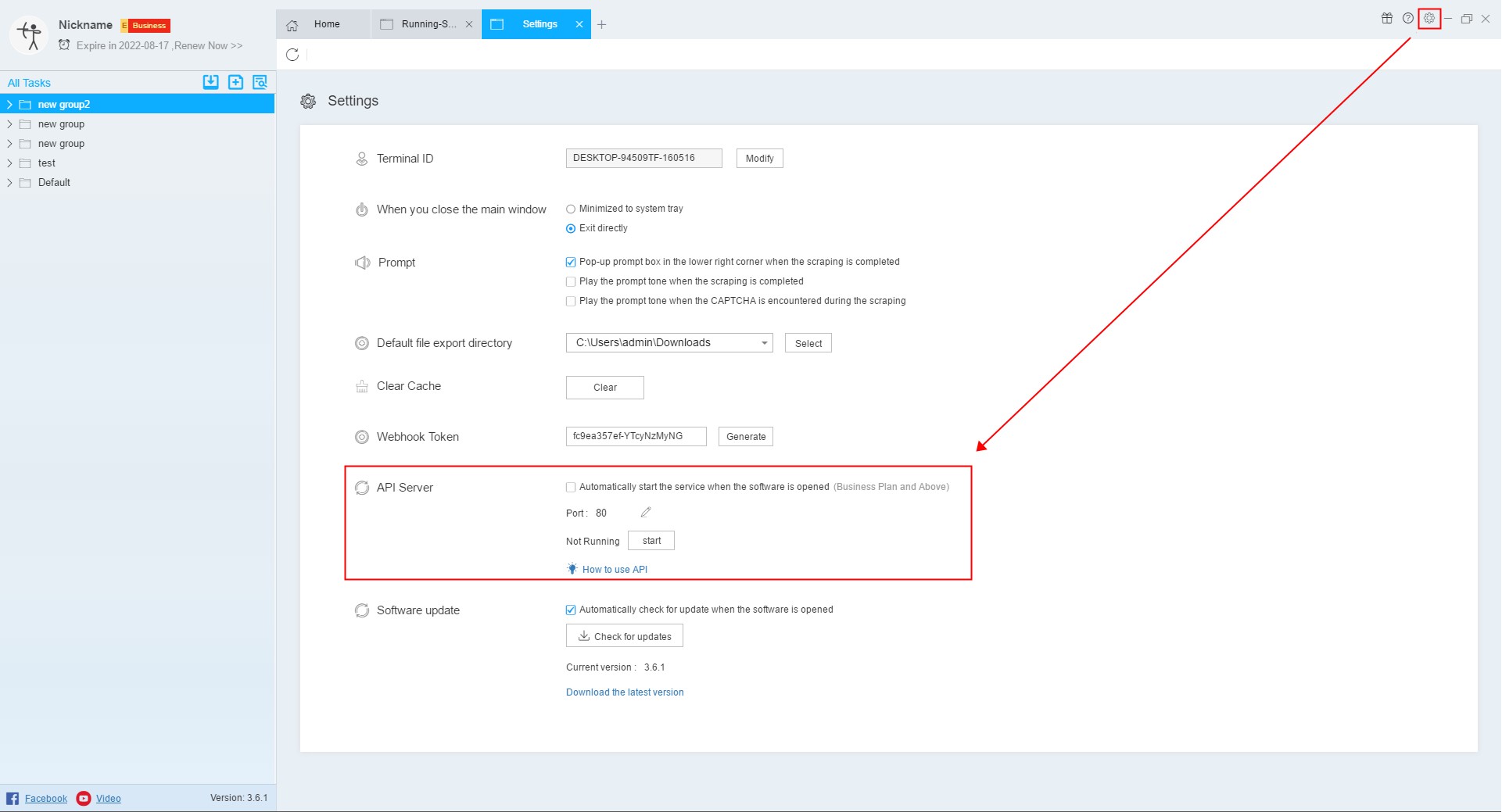
The default monitor port is 80, which you can change in the settings. The API server bind all the IPs of the terminal where ScrapeStorm running on.
For Example:
If your machine’s IP is 10.0.0.1, port is 80, then the base URL of RESTful API is http://10.0.0.1:80/
ScrapeStorm’s API supports both get and post requests, as follows:
1. Load all scraping tasks
Path:
GET /rest/v1/task/load
Parameters:
no
Return example:
{
"code": 0,
"msg": "Load scraping task succeeded"
}
【Note】 If there are more than 10 scraping tasks, it is recommended to call the Load interface first, and then call other interfaces.
2. Fetch the tasks list
Path:
GET /rest/v1/task/list
Parameters:
no
Return example:
{ "code": 0, "msg": "Request list success", "list": [ { "name": "test-task", "time_create": 1555911862, "task_id": 5090076, "type": "smart" //smart or flowchart } ] }
3. Fetch status of a task
Path:
GET /rest/v1/task/<task id>/status
Parameters:
no
Return example:
{ "code": 0, "msg": "Request list success", "status": "SLEEPING", "status_change_time": "1644492503" // the timestamp when the task was last stopped or slept }
4. Delete a task
Path:
GET /rest/v1/task/<task id>/delete
Parameters:
no
Return example:
{ "code": 0, "msg": "Delete success" }
5. Start a task
Path:
GET /rest/v1/task/<task id>/start
Parameters:
no
Return example:
{ "code": 0, "msg": "Start success" }
6. Stop a task
Path:
GET /rest/v1/task/<task id>/stop
Parameters:
no
Return example:
{ "code": 0, "msg": "Stop success" }
7. Copy a task
Path:
GET /rest/v1/task/<task id>/copy
Parameters:
| Parameters | Parameter Description |
| name | copy the crawler task name, the default original file name + “-copy”, optional |
| translate_chart | Whether the copied crawler task changes to advanced mode, the default is false, optional |
Return example:
{ "code": 0, "msg": "Copy success" }
8. Clear data of a task
Path:
GET /rest/v1/task/<task id>/data/clear
Parameters:
no
Return example:
{ "code": 0, "msg": "Clear data success" }