【Smart Mode】【Flowchart Mode】How to scrape from breakpoint | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial will show you how to scrape from breakpoint. ScrapeStormFree Download
During the scraping process, we may encounter an abnormal stop. If we want to start the task again from the last stop position, we need to scrape from breakpoint.
Due to various factors, the feature of automatically scraping from breakpoint is not yet available, and our engineers are also trying to overcome this problem. Currently there are two options for scraping from breakpoint:
Option 1: Through the function of deduplication, it can be applied to all modes, especially pages with rolling loads.
Option 2: By setting scraping range, modifying the URL or adding pre-operation, it can be applied to all modes, especially pages with page turning buttons.
Next, we will introduce these two options separately. You can judge and choose when scraping.
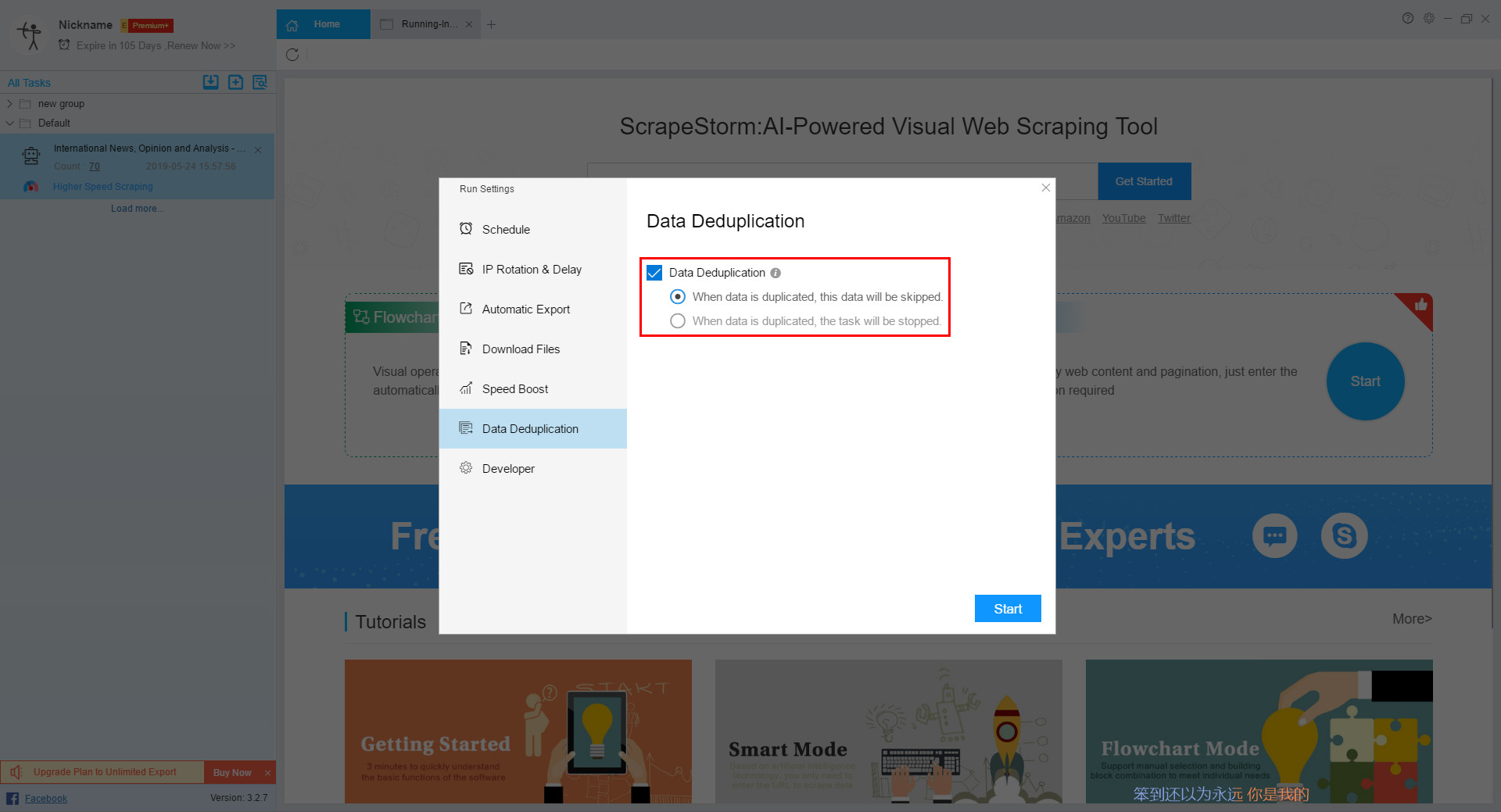
Option 1: Through the function of deduplication
Set the Data Deduplication when starting the task, and select “When data is duplicated, the data will be skipped”.
The solution is simple to set up, but it is less efficient. After the setup, the task will still start from the first page, and then skip all the data that has been scraped one by one.
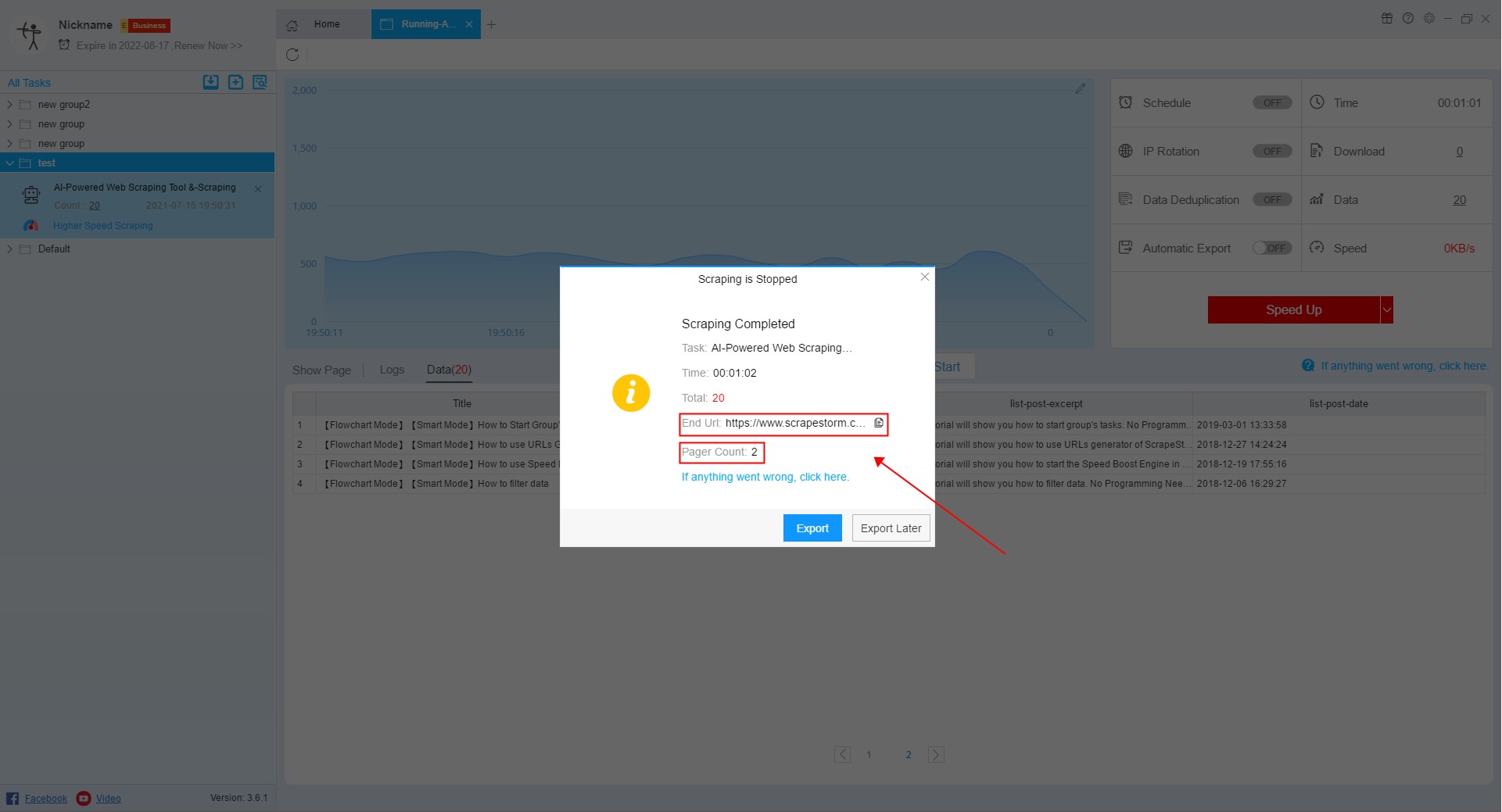
Option 2: By setting scraping range, modifying the URL or adding pre-operation
When a task stops, the stop interface of the software records the End URL and Pager Count when the current task scrapes to the last one. In general, the End URL is accurate, but the pager count may be more than the actual value, because if there is a page jam, there will be the number of empty pages.
You can use these two values as a reference for breakpoint.
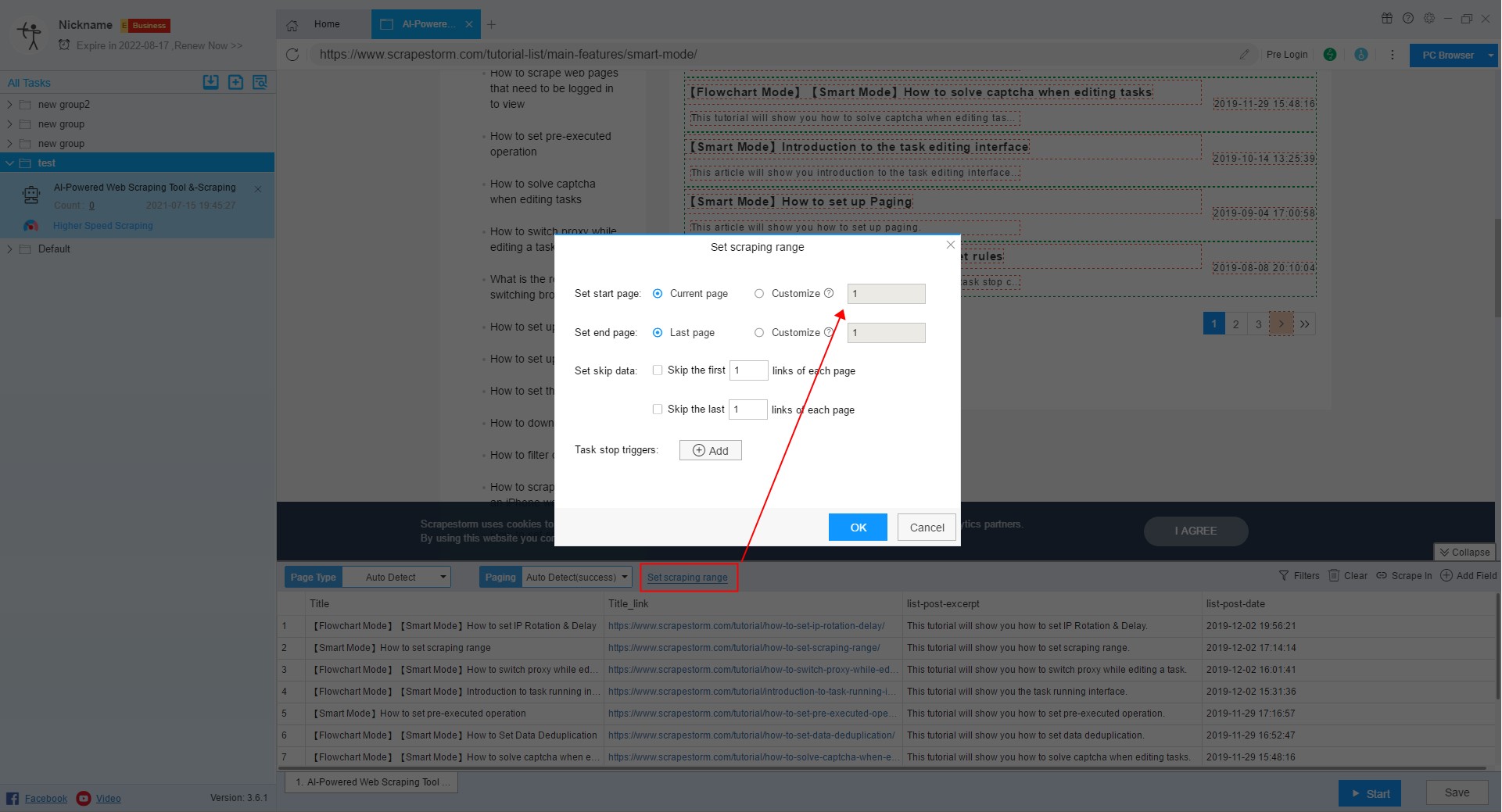
1. Set scraping range (for smart mode)
Step 1: Copy the End URL and refer to Pager Count to find the exact number of page flips.
Step 2: In smart mode, set start page in scraping range to the number of page flips in step 1.
2. Modify the URL or add a pre-operation
It can generally be divided into the following situations:
(1) Websites whose URLs will change as the page number changes (for smart mode or flowchart mode).
Like this:
https://www.scrapestorm.com/tutorial-list/main-features/smart-mode/page/1/
https://www.scrapestorm.com/tutorial-list/main-features/smart-mode/page/2/
https://www.scrapestorm.com/tutorial-list/main-features/smart-mode/page/3/
In this case, if the task stops when it reaches page 3, we can directly copy the URL of page 3, then modify the URL in the original task, and then scrape it again.
[Tips] Don’t click to clear the data if the previously scraped data needs to be retained.
(2) Websites whose URL does not change with the change of page number (for flowchart mode).
Websites like the following, no matter how the number of pages changes, the URL will not change:
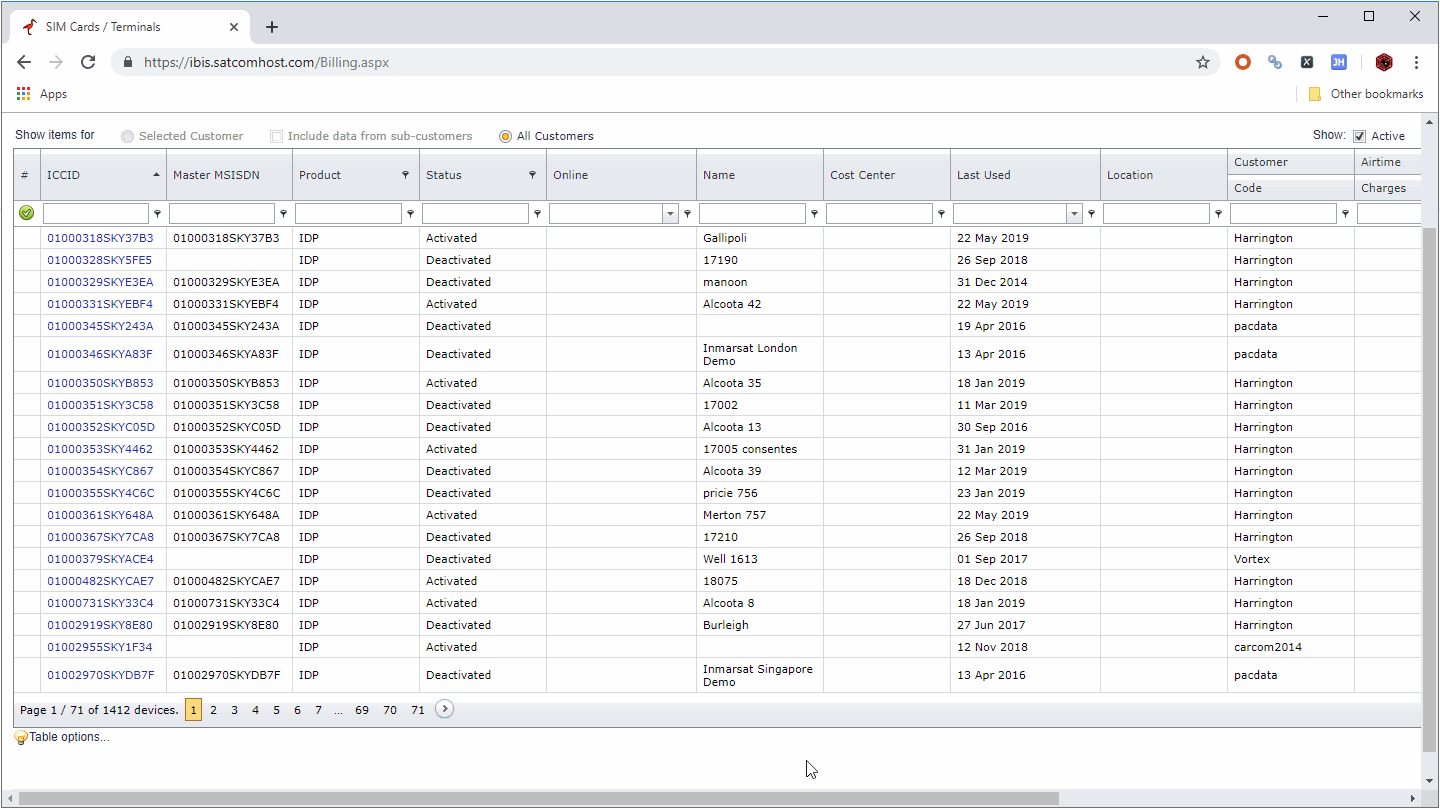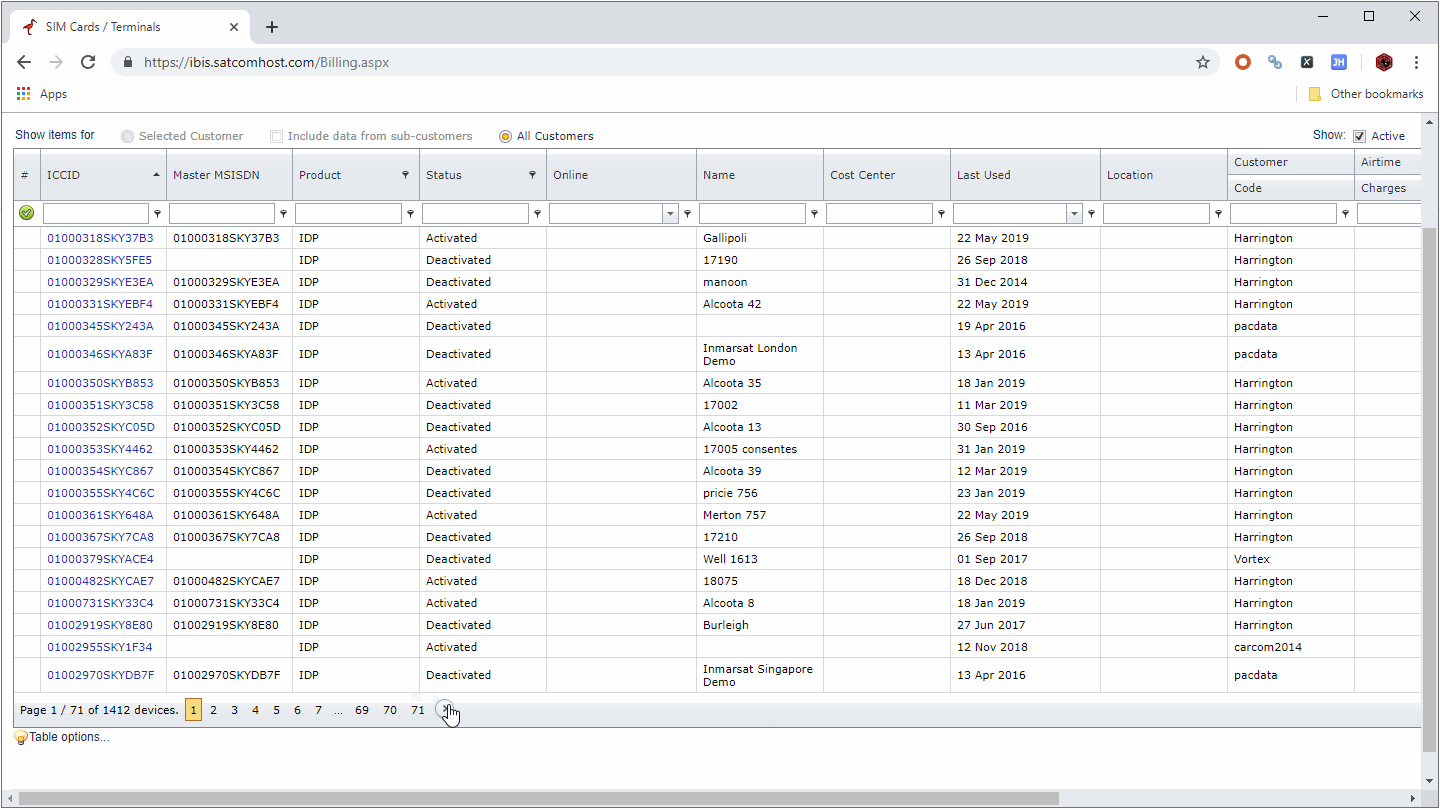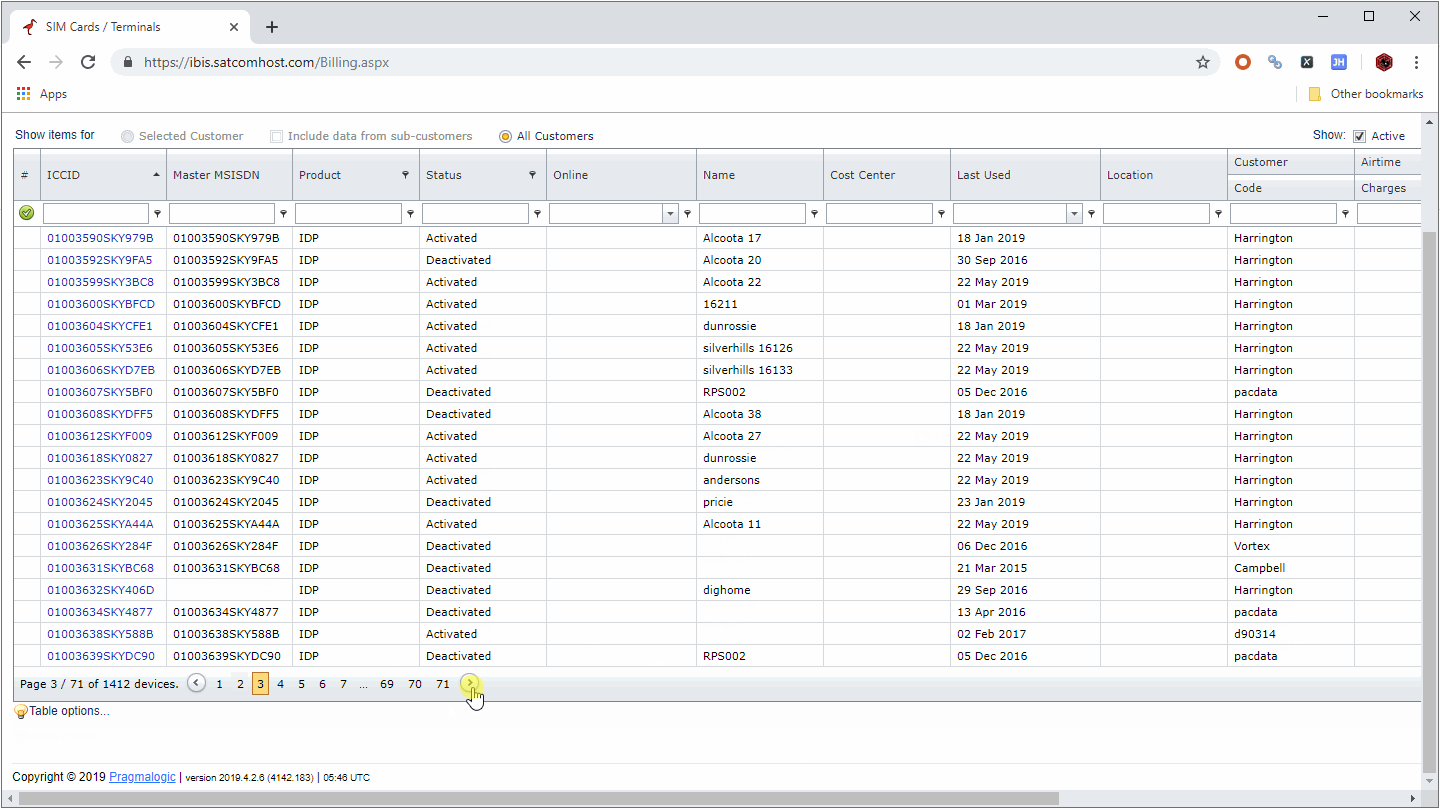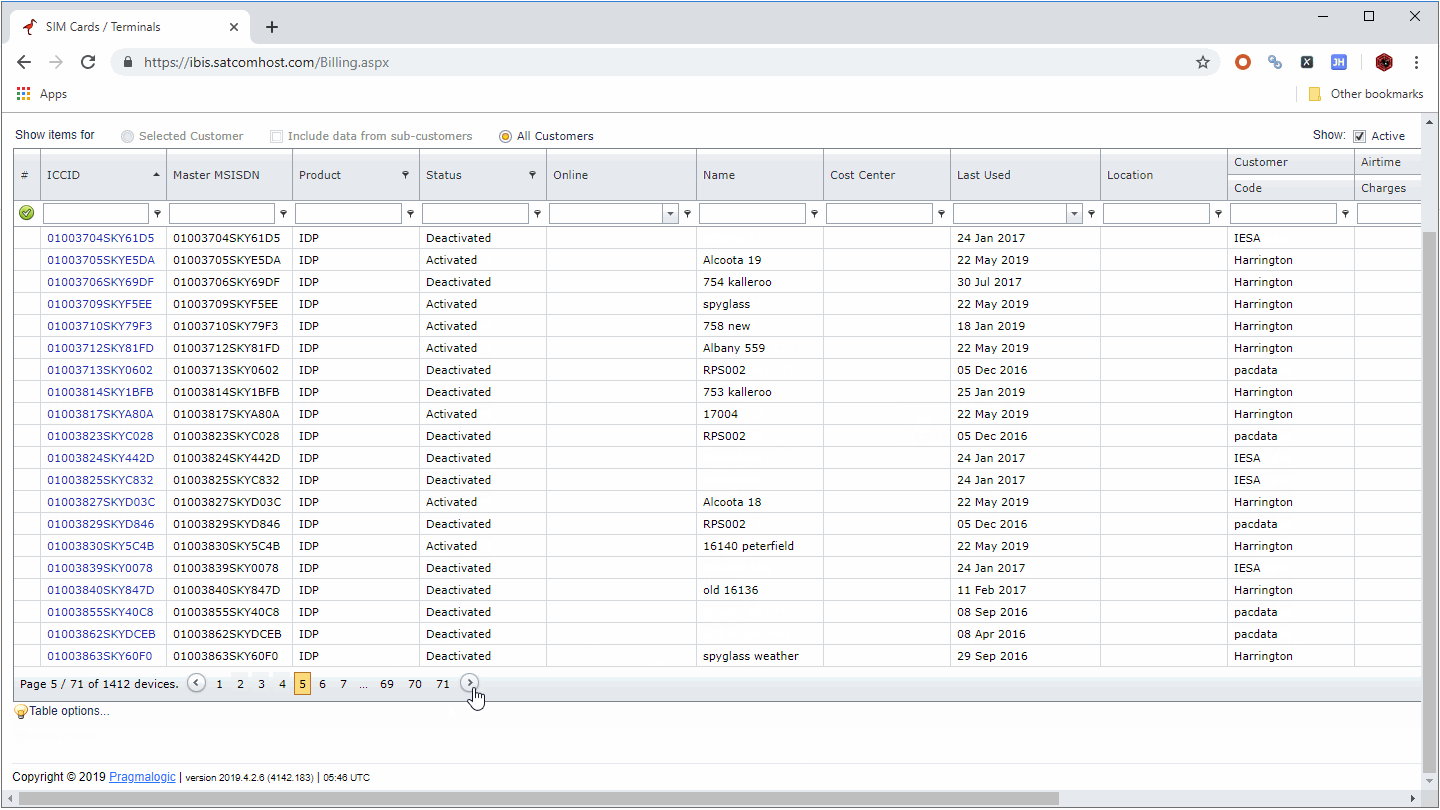
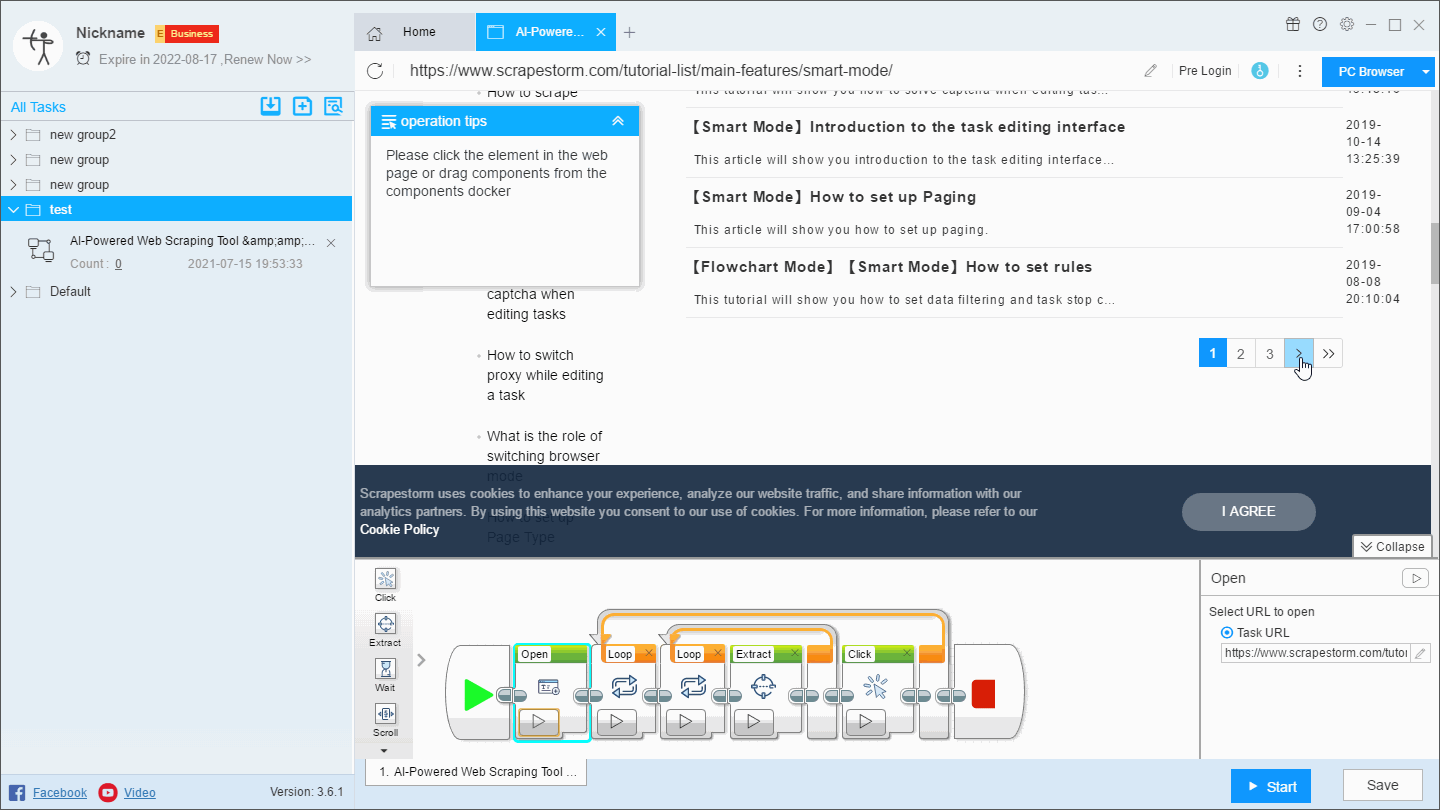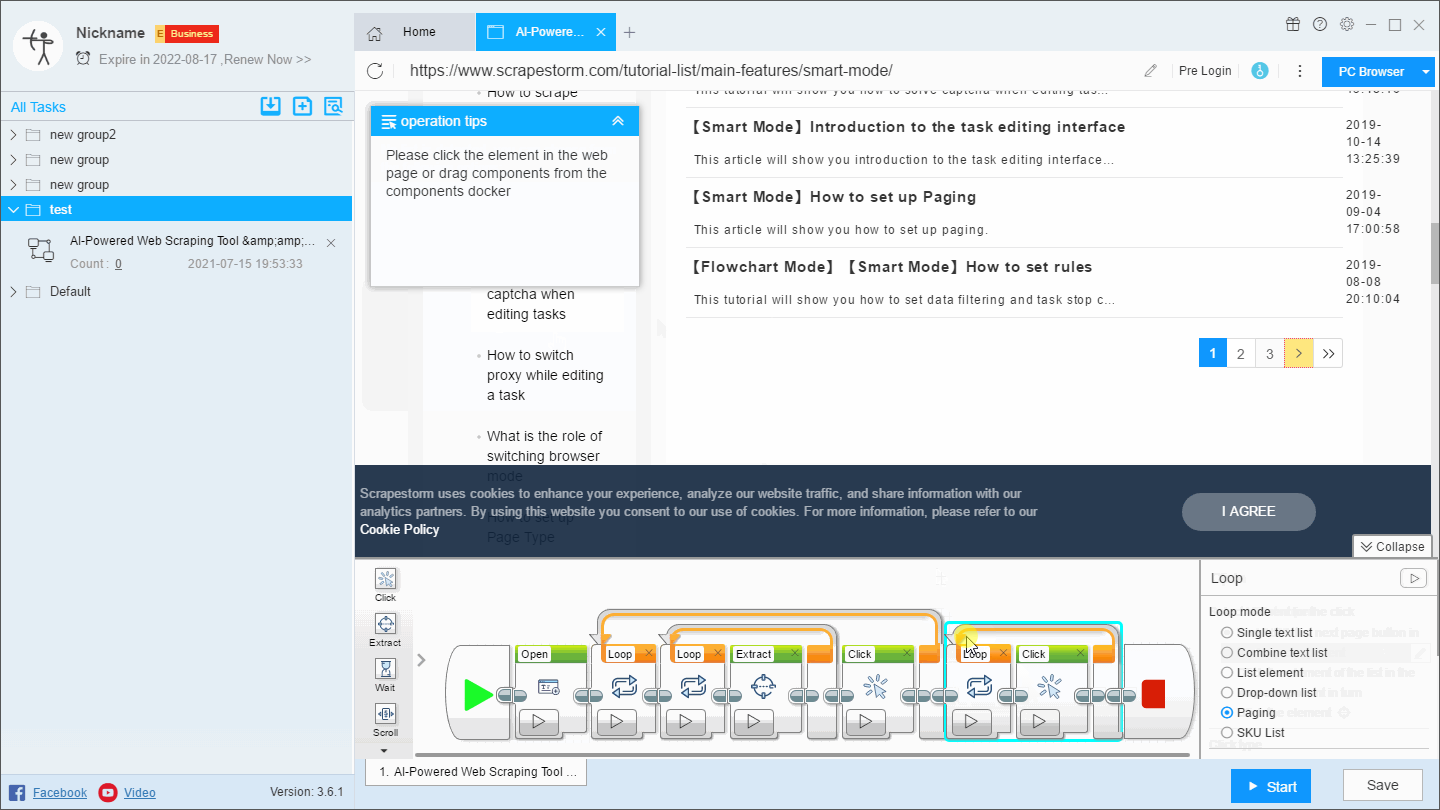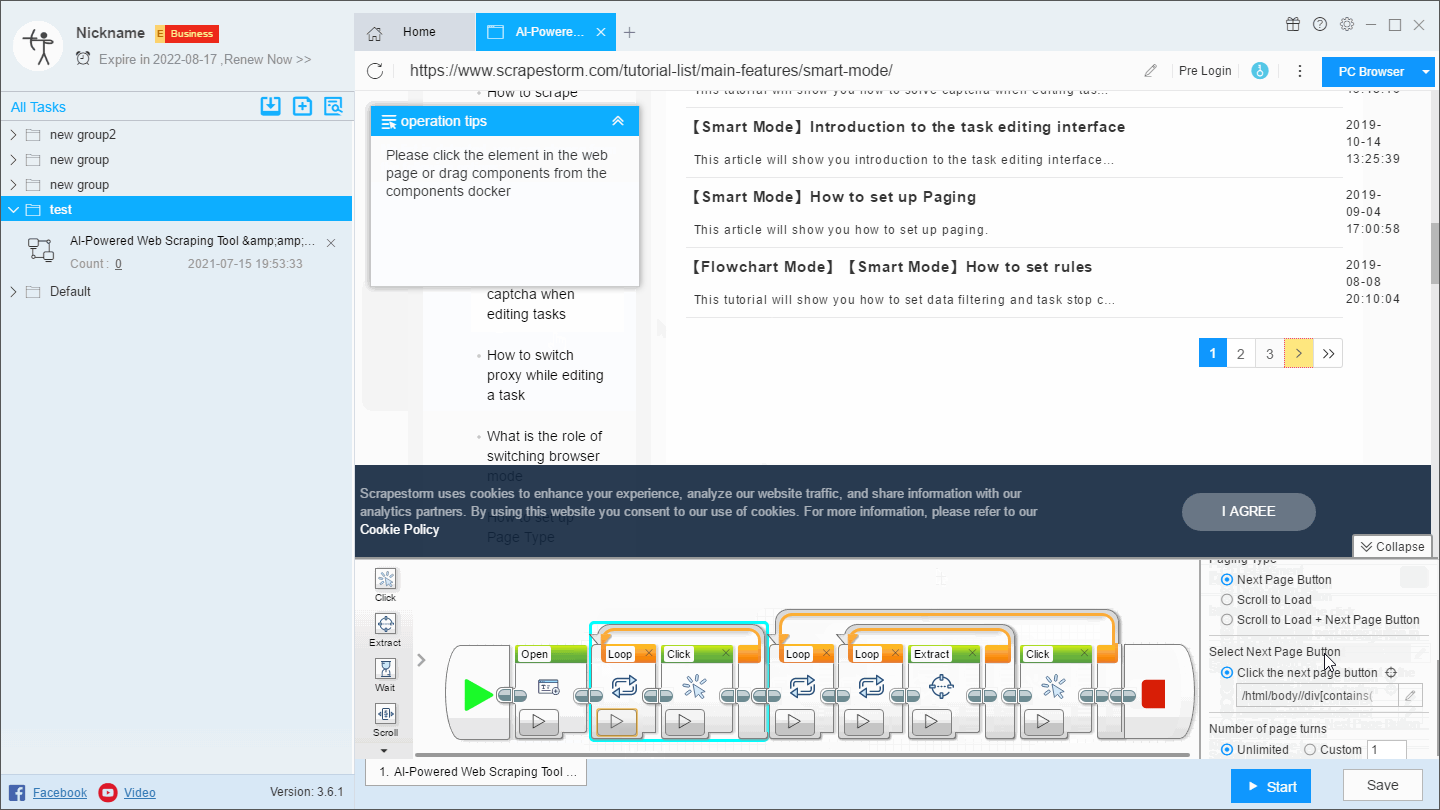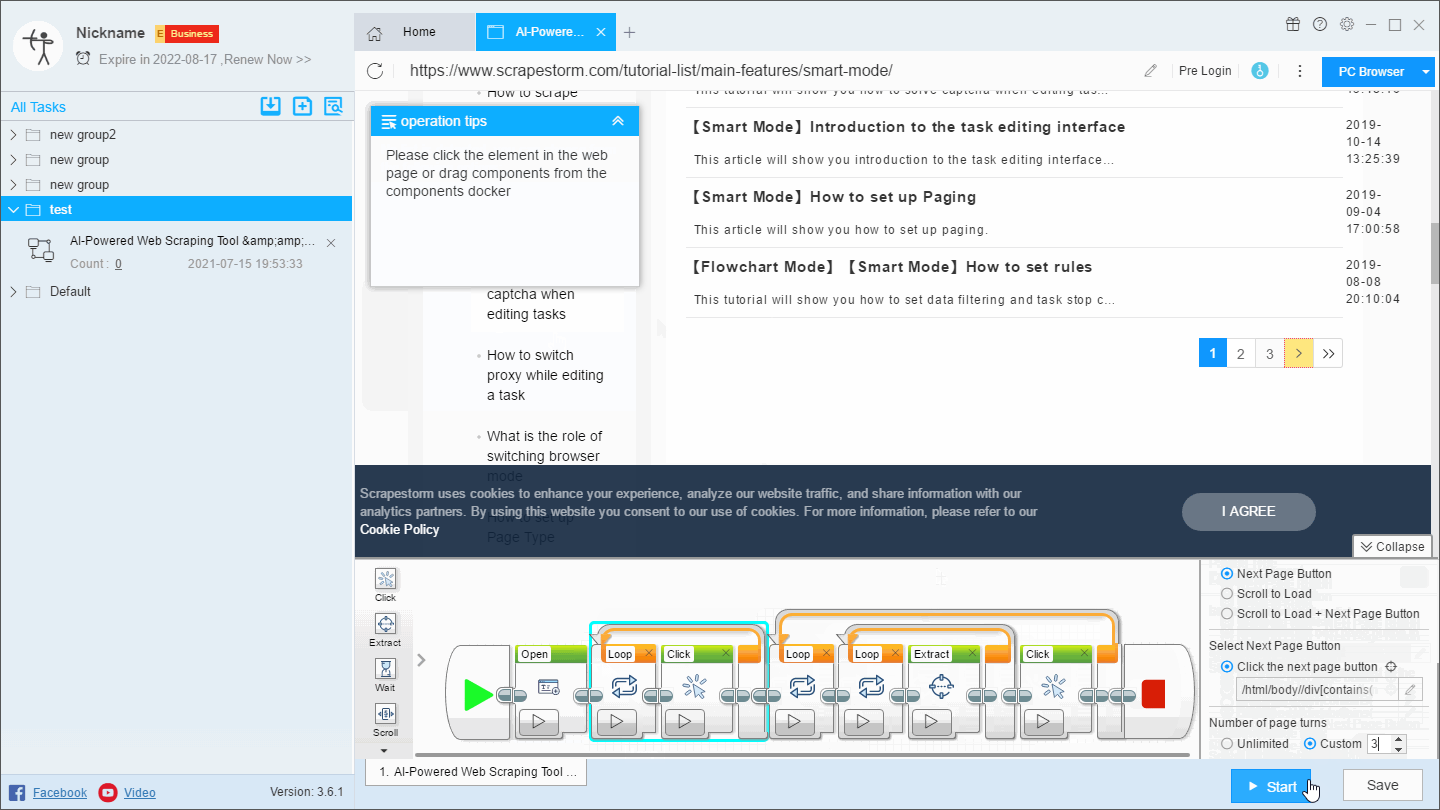
For this kind of website, we need to add a loop page after the Open component, we can create it by directly clicking the paging button or by dragging the component (some paging buttons may not be recognized by clicking).
This will perform an independent page flip before the scraping is started, and then get the page that was previously stopped.
This operation has the same effect as setting the scraping range in the first solution. It is mainly used in the flowchart mode. The specific operation is as follows: