【Smart Mode】Basic operational procedures | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial demonstrates the basic operational procedures of Smart Mode. ScrapeStormFree Download
1. Enter the correct URL
ScrapeStorm supports single and multiple URL scraping, and supports Manual Input, File Import and URLs Generator.
For more details, please refer to the following tutorial:
How to create a smart mode task

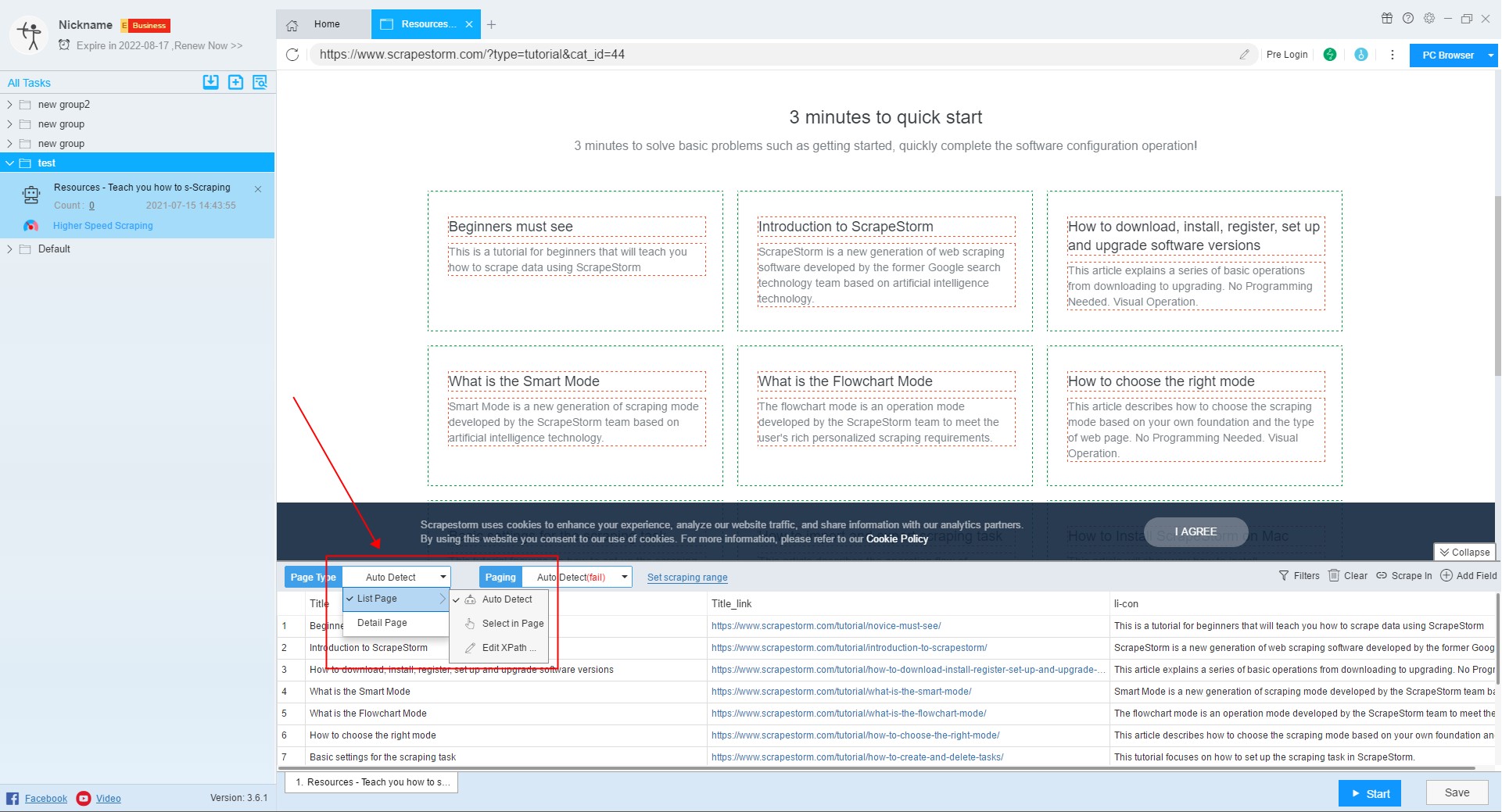
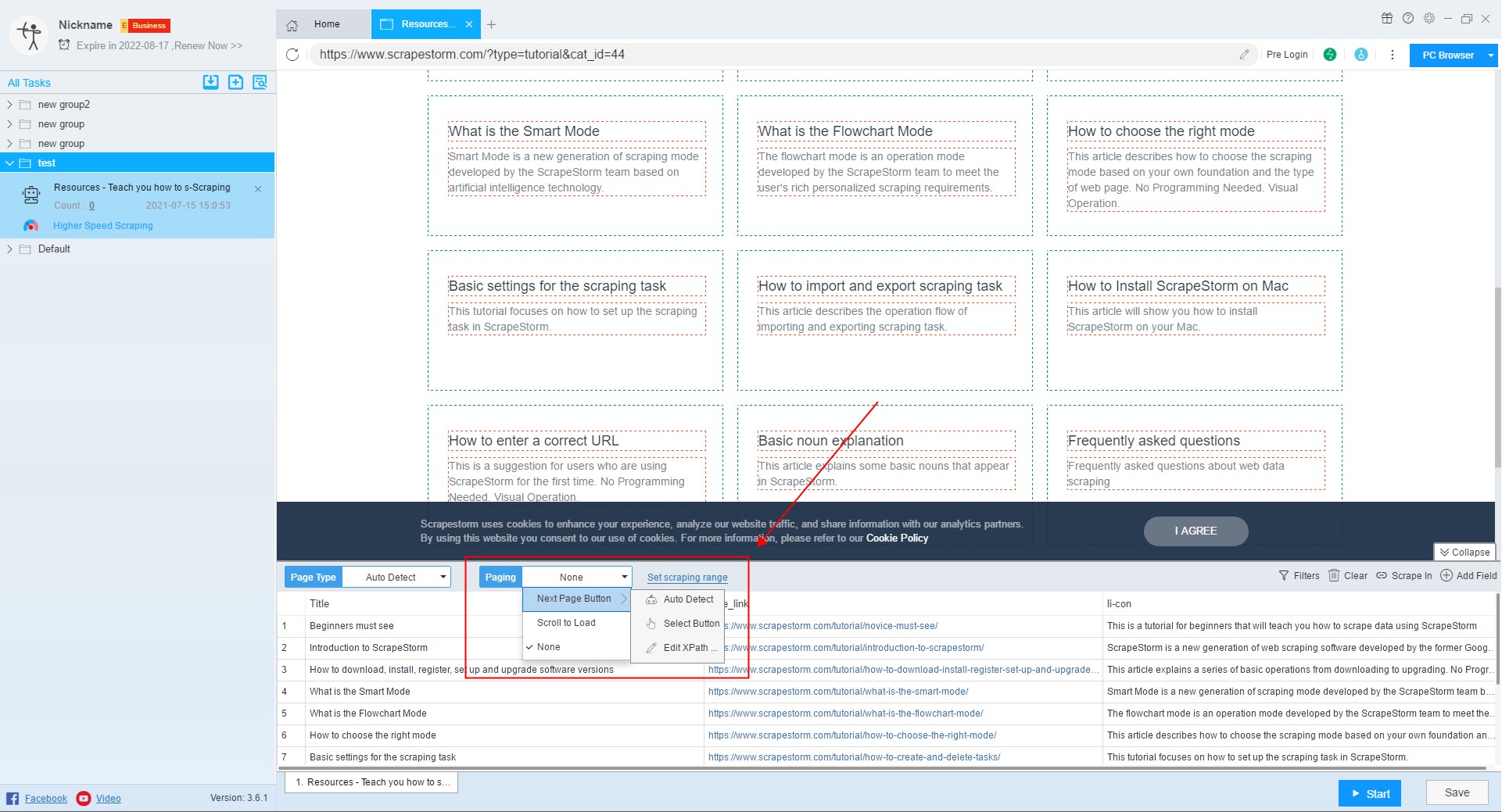
2. Set page type and paging
After selecting the URL to extract, we set the page type the paging.
The page types can be divided into two categories, one is the detail page, the other is the list page, and the Smart Mode is suitable for extracting the contents of detail page, list page, list page & detail page.
After the page type is determined, we can set the paging.
For more details, please refer to the following tutorials:
How to scrape a list page & detail page
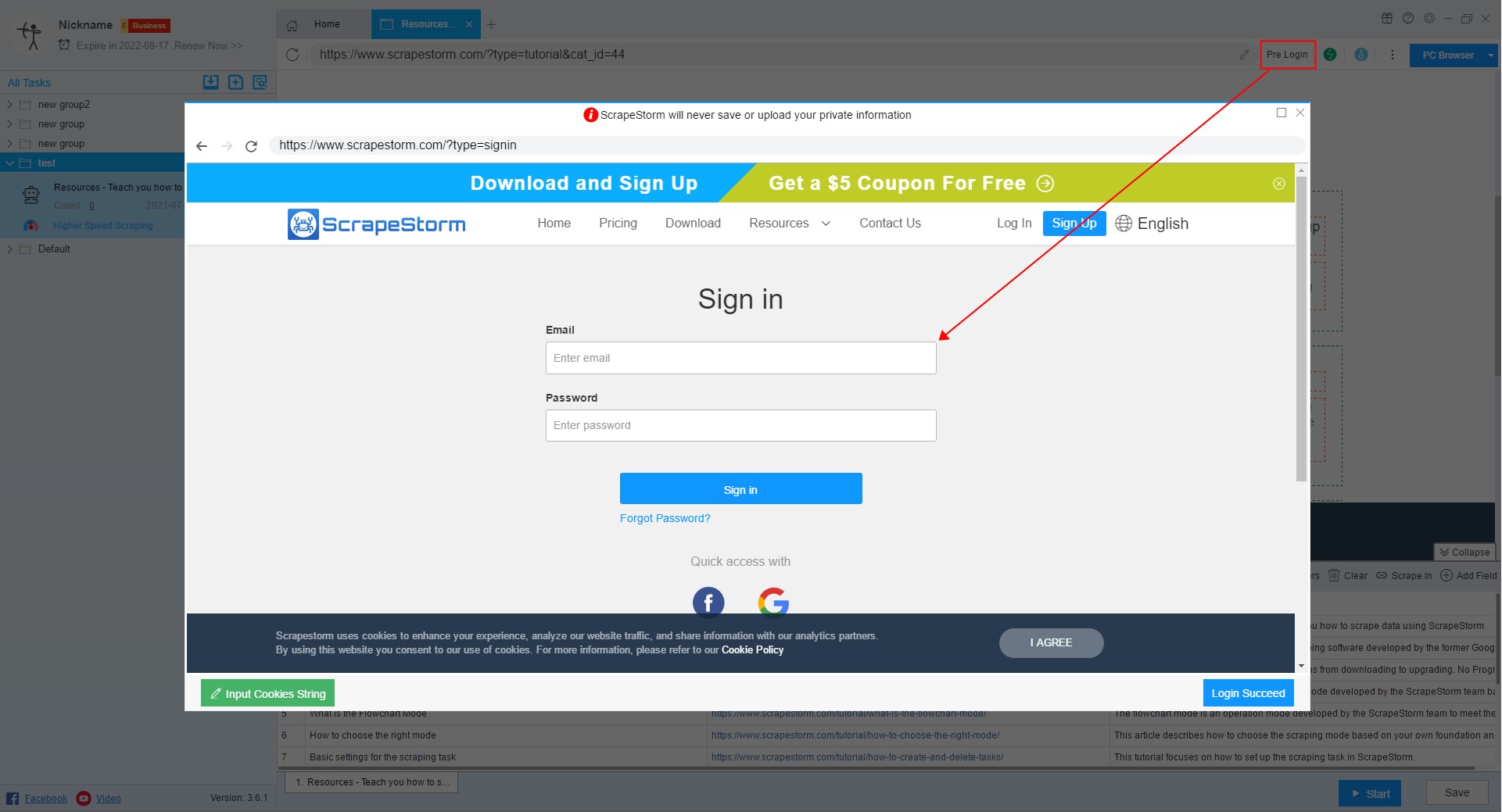
3. Pre Login
When you encounter a webpage that requires login, you can click this button to use the Pre Login function.
For more details, please refer to the following tutorial:
How to scrape web pages that need to be logged in to view
4. Pre-executed operation
In the process of editing a task, if you need to perform a click operation, you can use the pre-executed operation.
For more details, please refer to the following tutorial:
How to set pre-executed operation
5. Solve Captcha
When you encounter captcha while editing a task, you can click this button to use the Solve Captcha function.
6. Open Proxy
When you encounter captcha or other anti-climbing on the home page, you can use the switch proxy function in addition to the solve captcha function.
Click here to learn more about Open Proxy.
7. Web Security Option
You can try this feature when you encounter a web page exception, but be aware that opening this option may cause some content on the page to not be scraped (such as content in an iframe).
8. Advanced Settings
You can monitor pushStates and block URLs in the advanced settings.
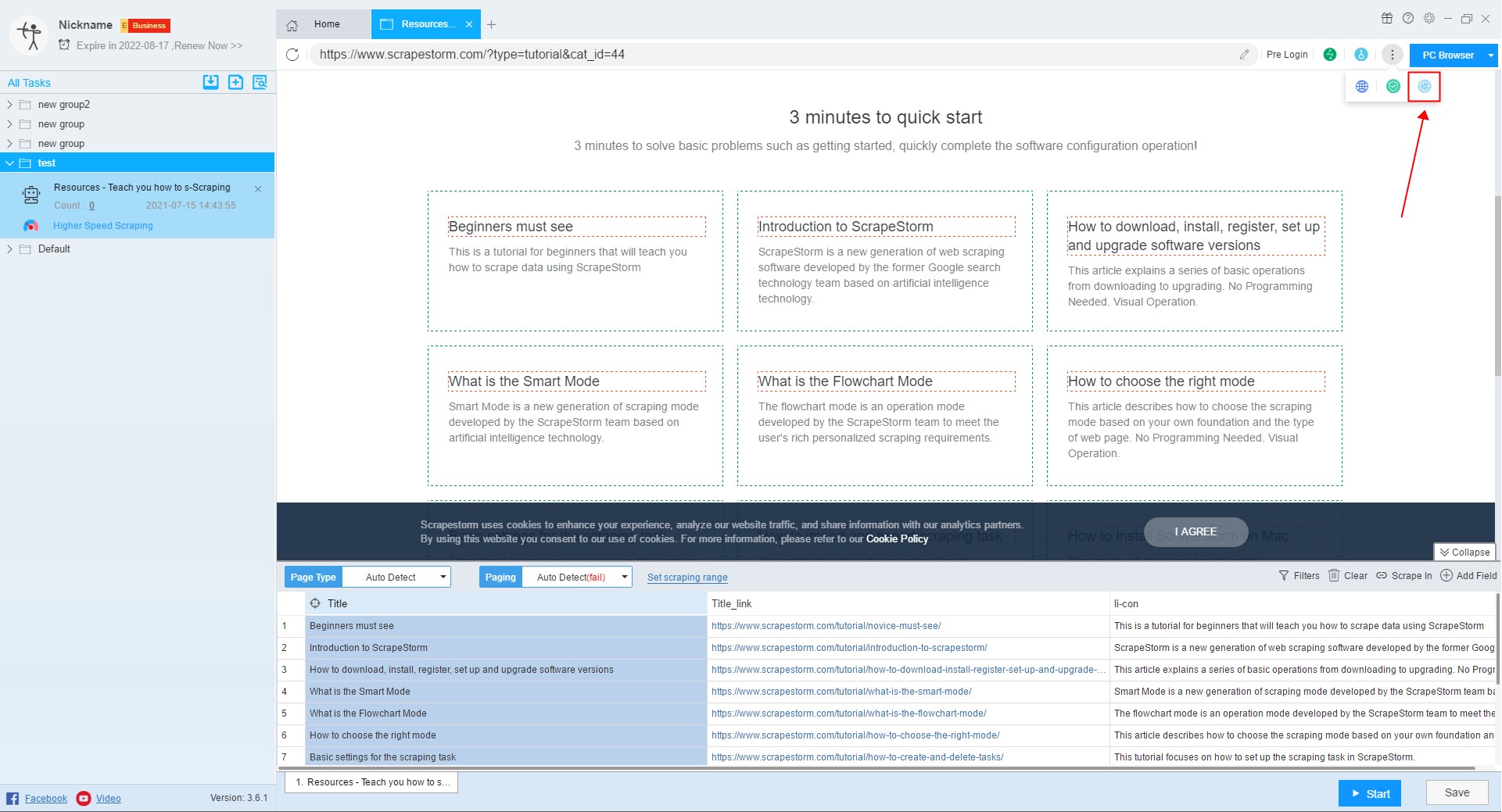
9. Switch Browser
Some webpages display different content on the computer and on the mobile phone. The software generally scraps the webpage of the computer version by default. If the user wants to scrape the webpage of the mobile version, it can be scraped by switching the browser mode.
For more details, please refer to the following tutorial:
What is the role of switching browser mode
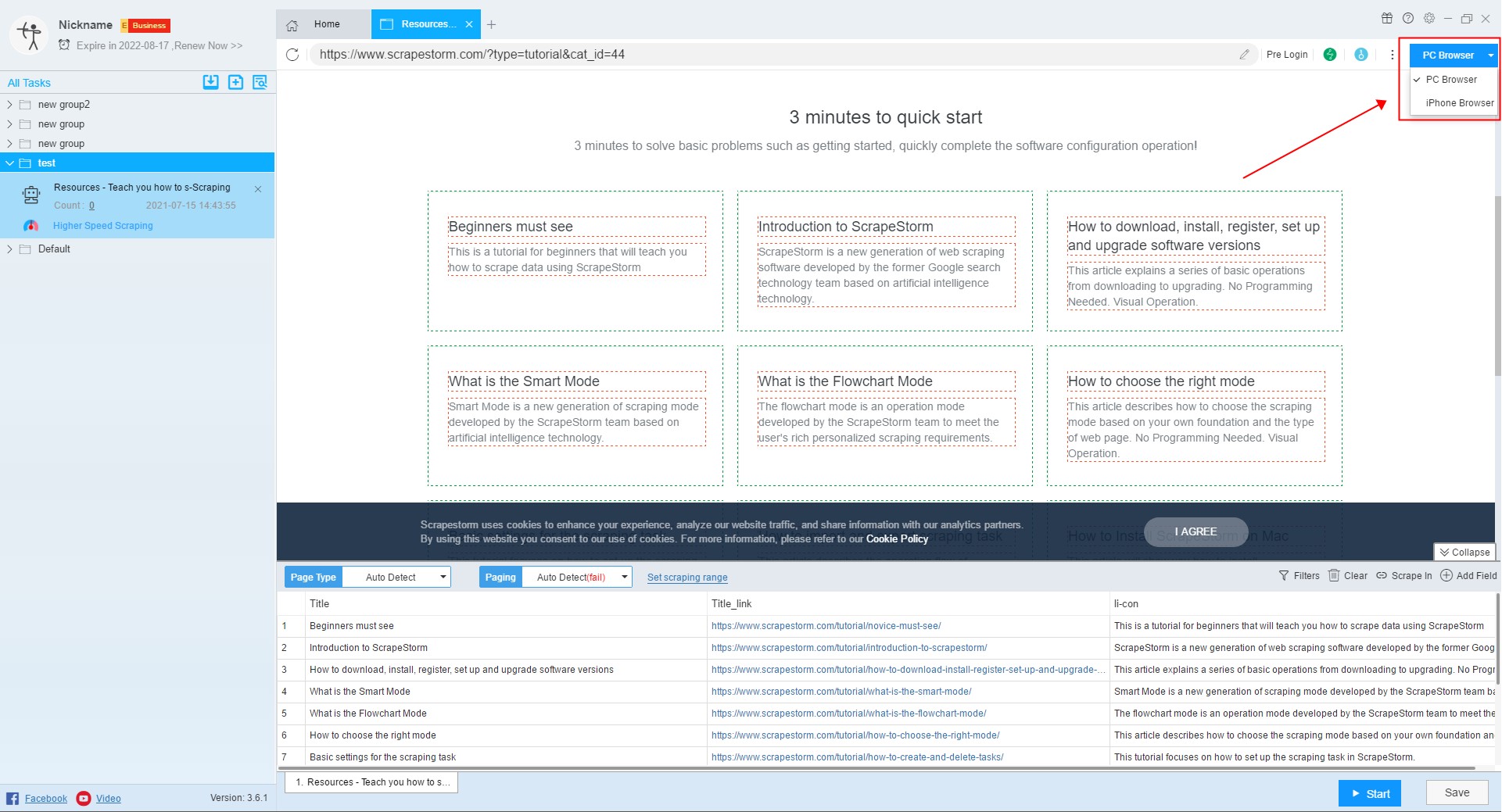
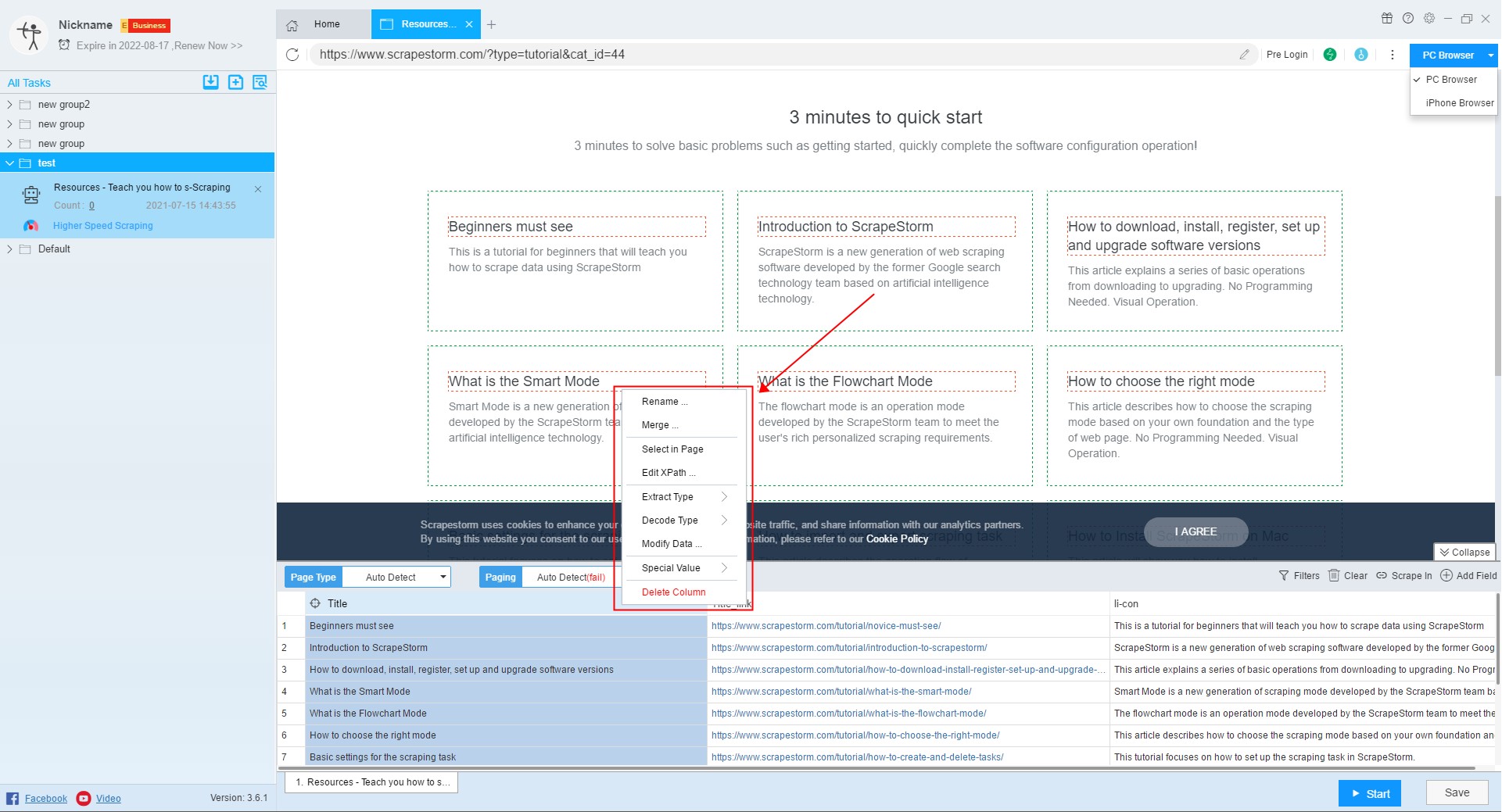
10. Set the scraping field
In smart mode, the software will automatically detect the data on the page and display it to the preview window, and users can set the fields according to needs.
For more details, please refer to the following tutorial:
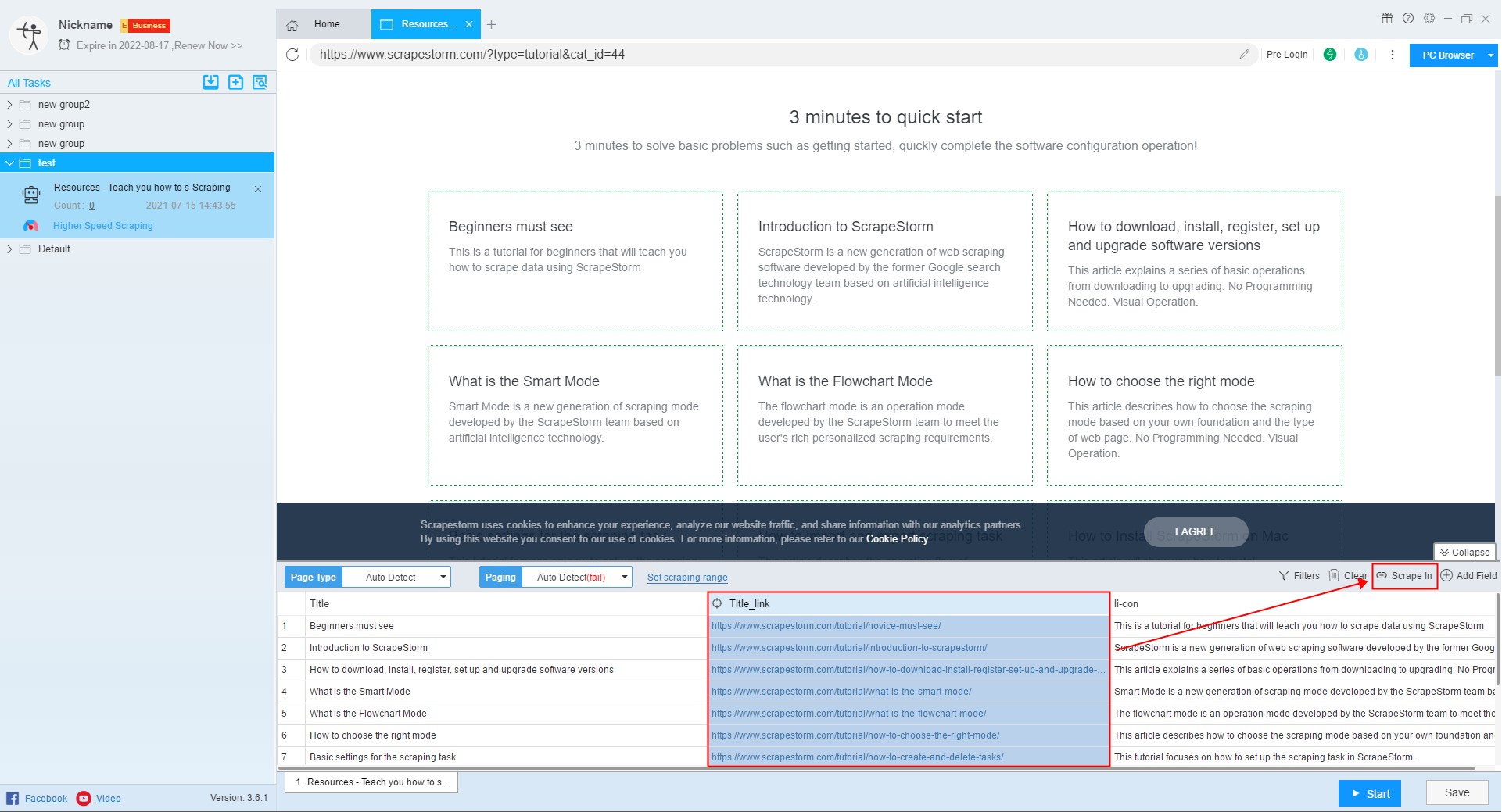
11. Scrape In
If you need to scrape the data of the detail page, you can click the Scrape In button, or click a link directly to enter the detail page.
For more details, please refer to the following tutorial:
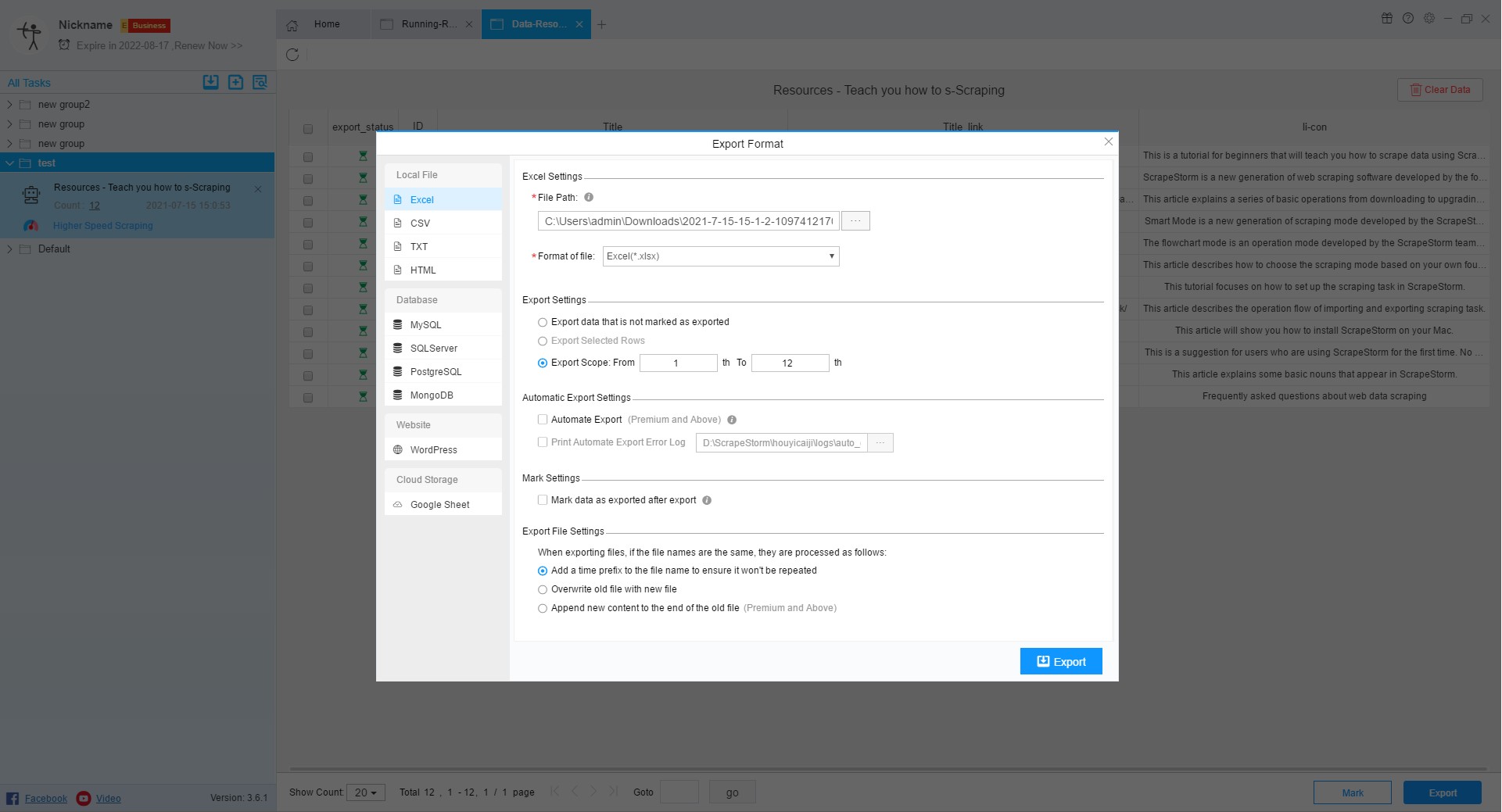
12. Set the filter/scraping range
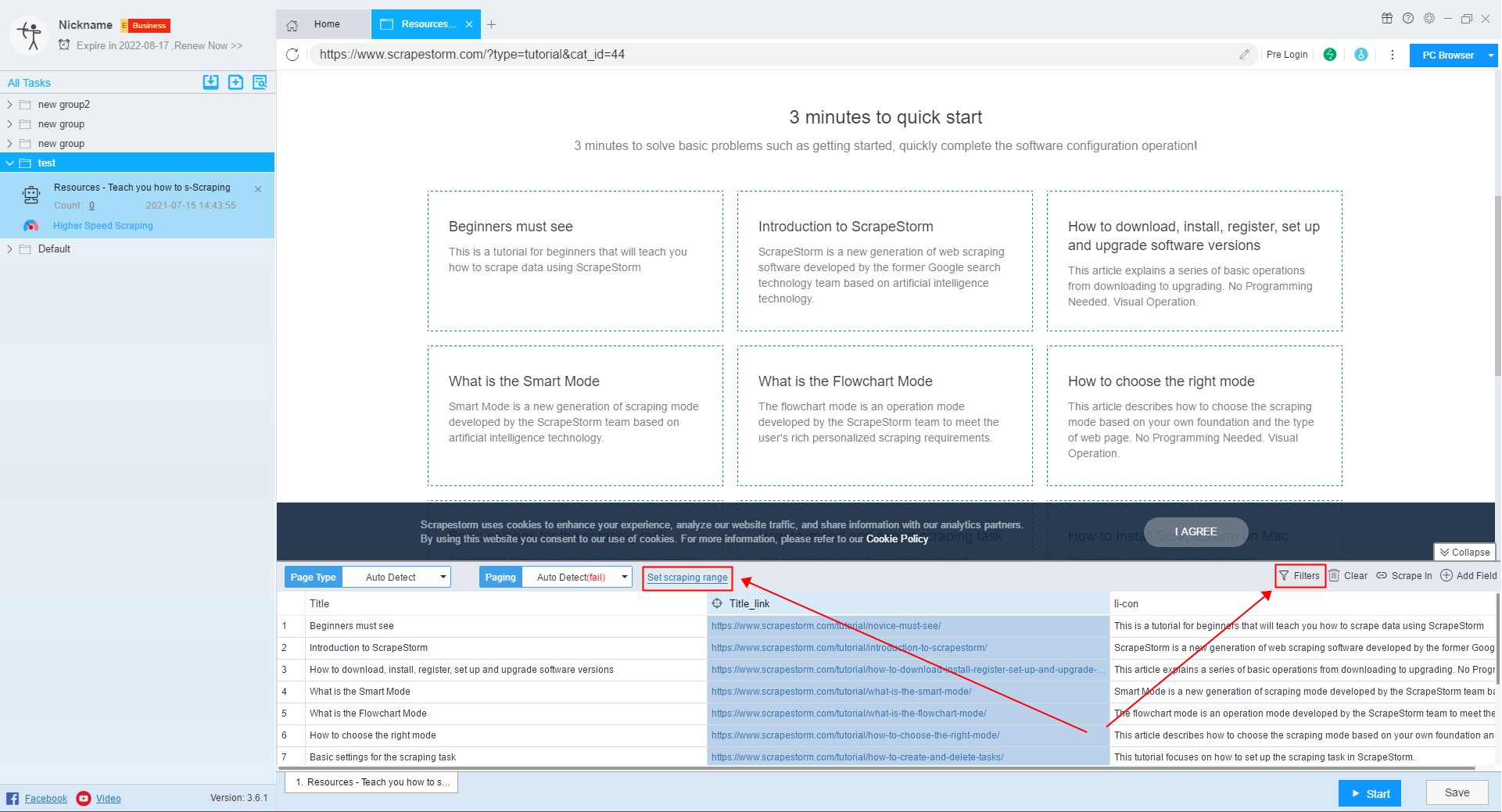
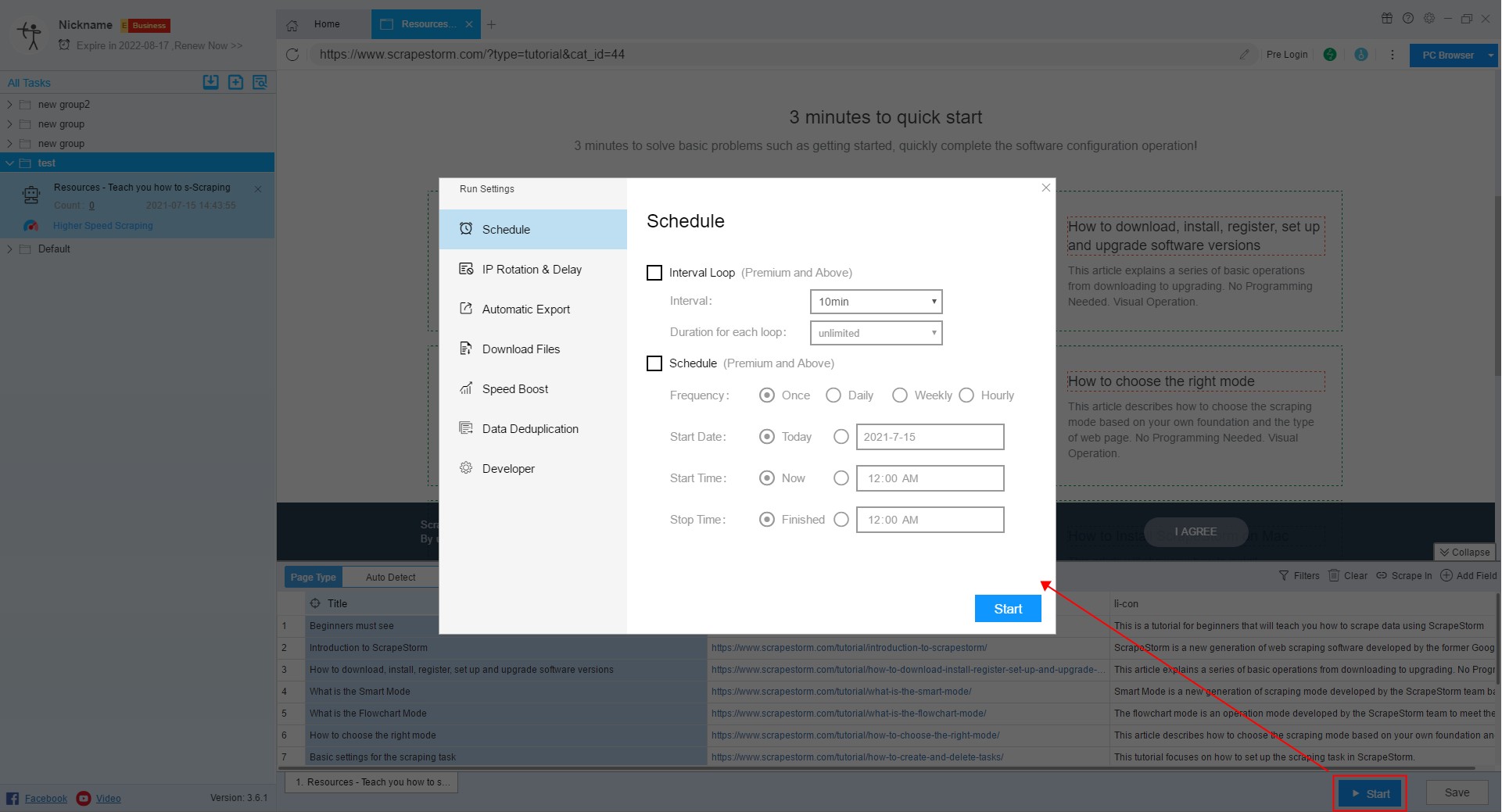
13. Run settings
Before starting the task, we need to configure the task, including Schedule, IP Rotation & Delay, automatic export, Download Files, Speed Boost, Data Deduplication and Developer.
For more details, please refer to the following tutorial:
How to configure the scraping task
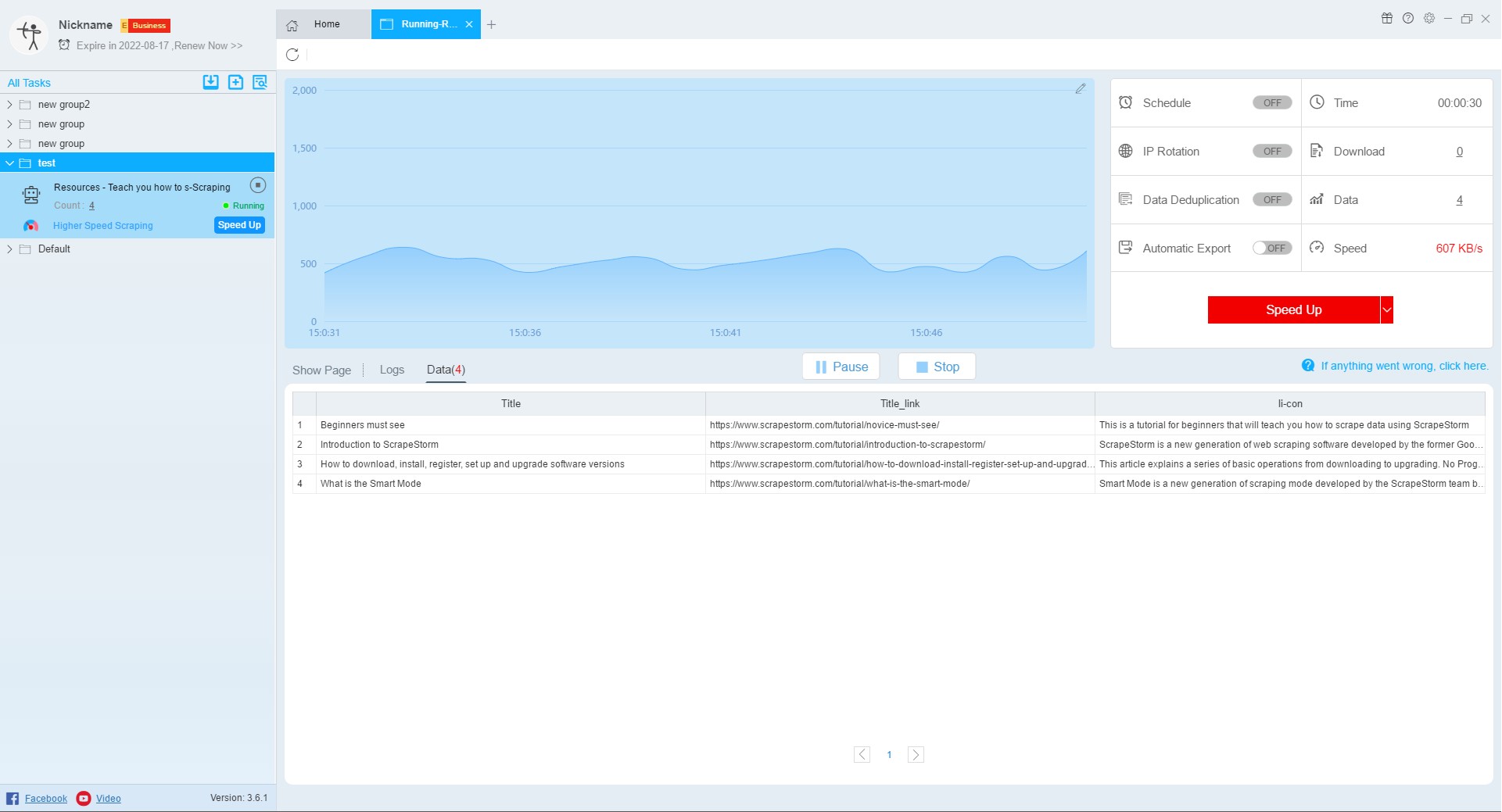
14. Run interface
After starting the task, it will jump to the data running interface. On this interface, the user can see the scraping of the data.
15. View scraping results and export data
After the task is over, the user can view the scraping results and export the data.
For more details, please refer to the following tutorial:
How to export the scraping results