【Smart Mode】【Flowchart Mode】How to Set Data Deduplication | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial will show you how to set data deduplication. ScrapeStormFree Download
Data Deduplication refers to filtering out duplicate data that may be encountered during task scraping. Data deduplication requires scrapping all the data before filtering. Therefore, turning on this function will make the scraping speed slower.
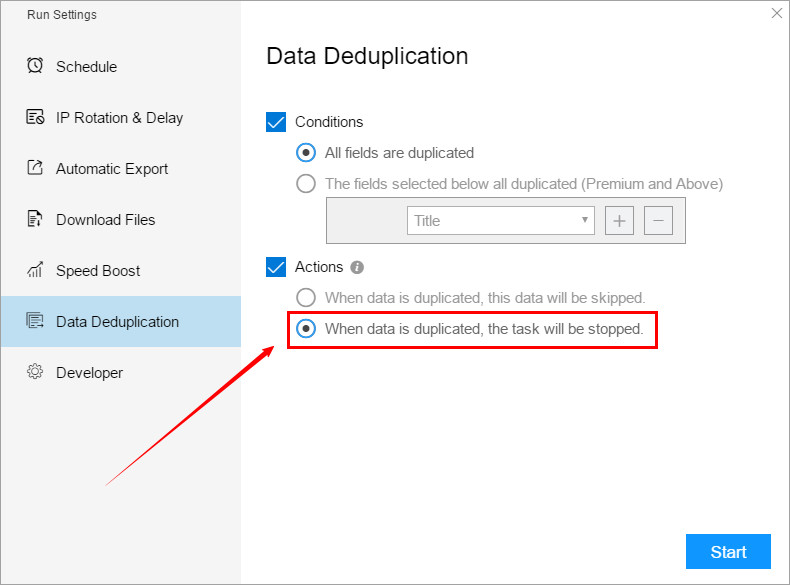
In the editing task interface, click the “Start” button in the lower right corner to open the running settings, and click the “Data Deduplication” option to switch to the data deduplication setting interface.
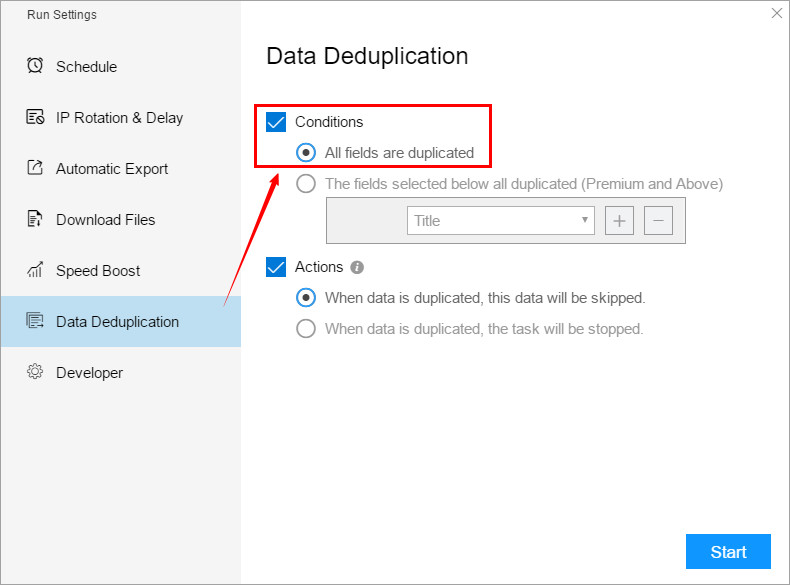
1. Conditions
(1) All fields are duplicated
Selecting “All fields are duplicated” means that the two rows of data must be exactly the same for the software to perform deduplication and filter out a duplicate. If one field in the two rows of data is different and the other fields have the same data, then this data is not determined as duplicate data, and the software will scrape these two data.
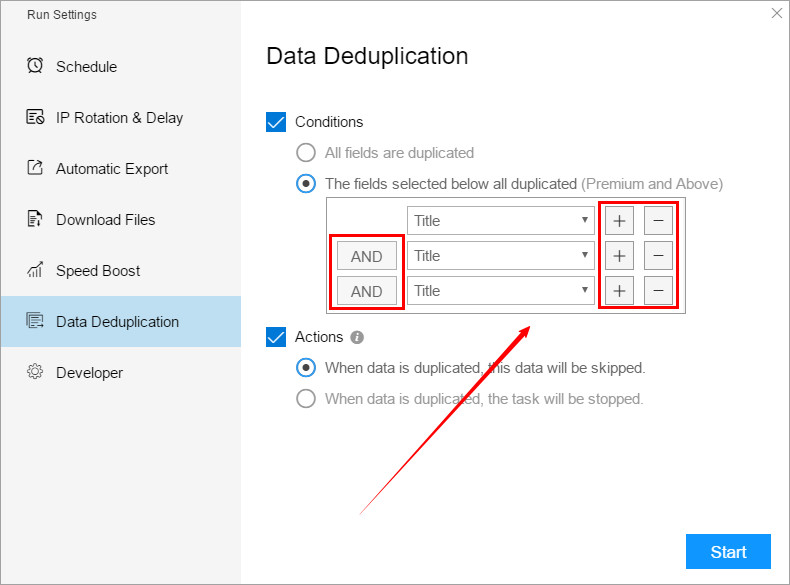
(2) The fields selected below all duplicated
When this condition is selected, the software can perform deduplication according to one or some fields. As long as the data in the field with the deduplication condition set is repeated, it can be determined as duplicate data, and only the next data is retained.
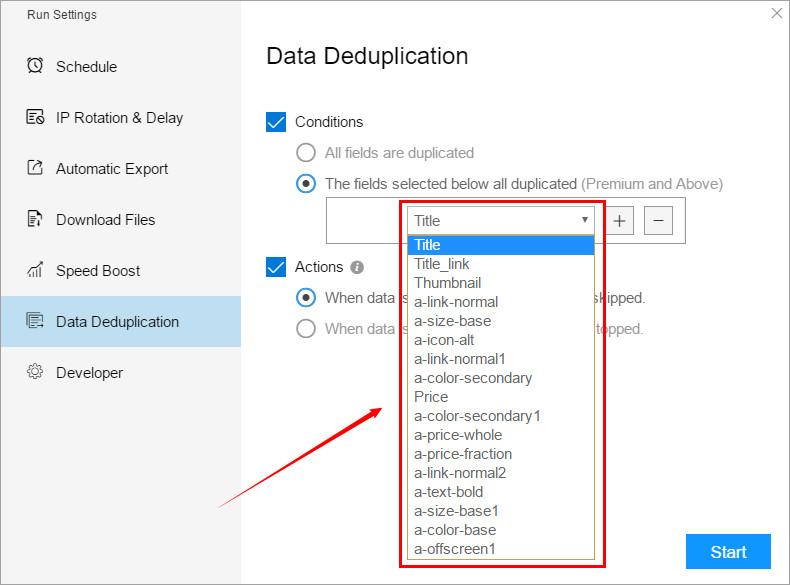
This can set multiple fields, click the “+” or “-” symbol to set, the relationship between multiple fields is “AND” relationship, that is, if two fields are set, both fields 1 and 2 must be the same Under the premise, the software will filter out this data.
2. Actions
(1) When data is duplicated, this data will be skipped
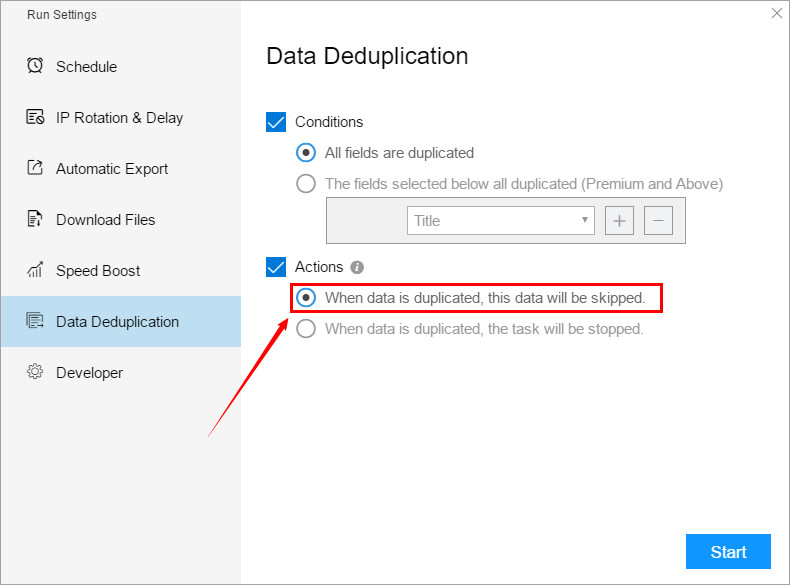
(2) When data is duplicated, this task will be stopped