Data Redundancy | Web Scraping Tool | ScrapeStorm
Abstract:Data redundancy refers to the situation where the same data is stored multiple times during the data storage process. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Data redundancy refers to the situation where the same data is stored multiple times during the data storage process. These duplicate data may appear in different locations of the same data set or may be scattered in different data storage systems. It can be unintentional (such as caused by system design defects) or intentional (to improve data reliability, performance, etc.).
Applicable Scene
It is suitable for scenarios with extremely high requirements for data availability and fault tolerance. For example, in banking systems, data redundancy technology is used to back up key data in multiple storage devices or geographical locations to prevent data loss due to hardware failure, natural disasters, etc. Large e-commerce platforms, in order to cope with high concurrent access, will cache data such as popular product information to avoid frequent reading from the main database and improve system response speed.
Pros: Improve data reliability to ensure business continuity, improve system performance to speed up response, and simplify data access to make operations more efficient.
Cons: Increase storage costs, cause data inconsistency problems, and reduce data maintenance efficiency.
Legend
1. Data Redundancy.
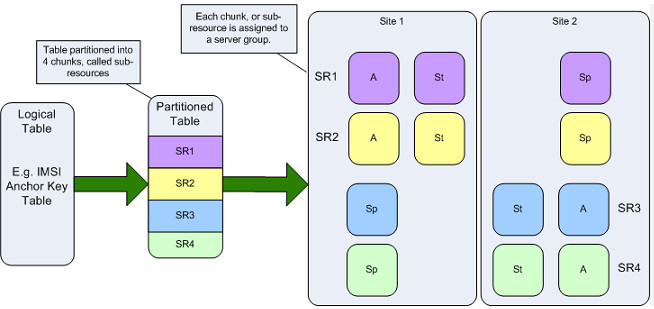
2. Data Redundancy.
Related Article
Reference Link
https://en.wikipedia.org/wiki/Data_redundancy
https://www.ibm.com/think/topics/data-redundancy
https://www.techtarget.com/searchstorage/definition/redundant