【Smart Mode】【Flowchart Mode】How to configure the scraping task | Web Scraping Tool | ScrapeStorm
Abstract:This tutorial will show you how to configure the scraping task. No Programming Needed. Visual Operation. ScrapeStormFree Download
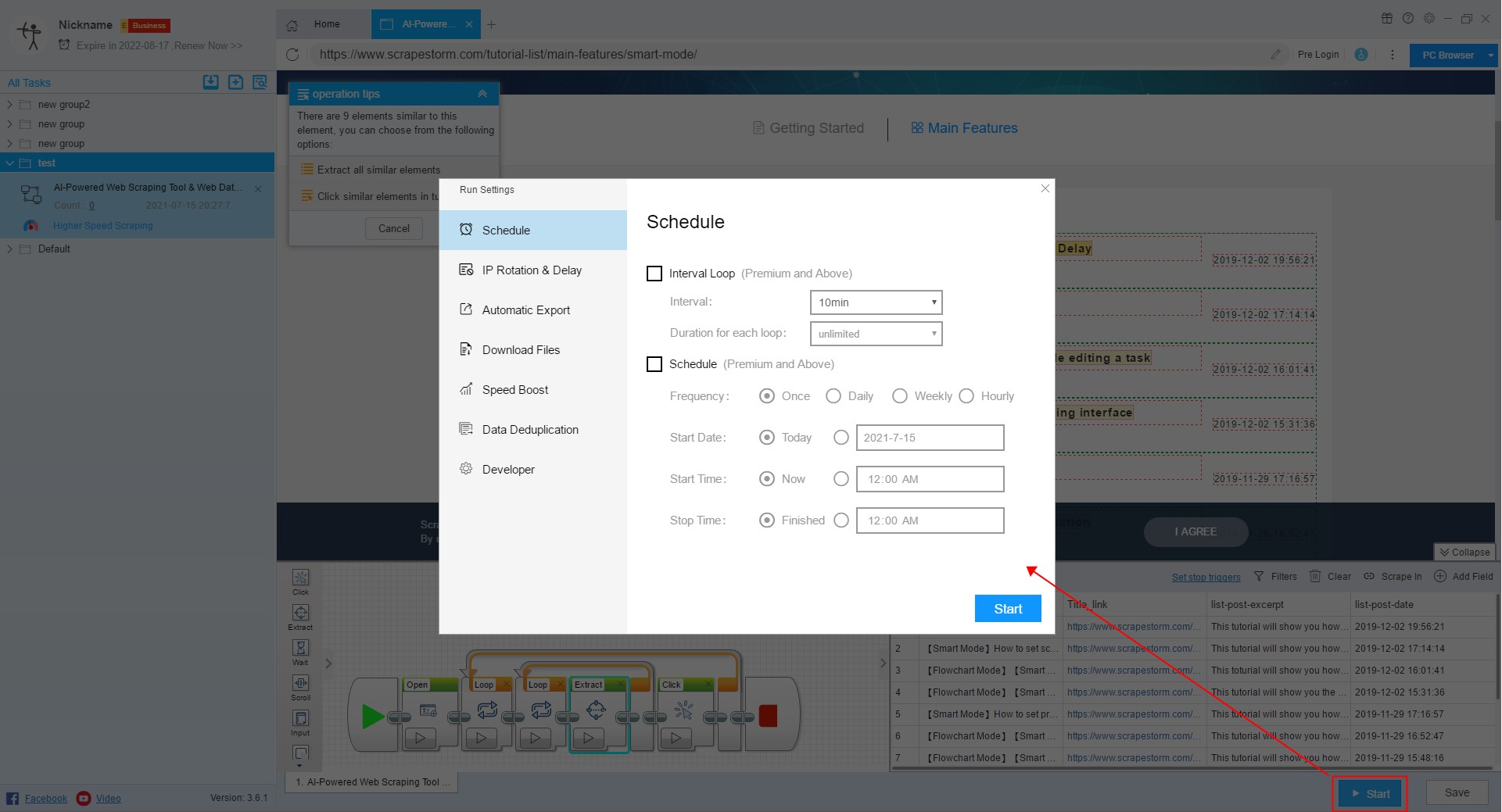
In the task editing interface, click the “Start” button in the lower right corner to open the run setting interface. We can configure the task in the run setting interface.
Specific settings include Schedule, IP Rotation & Delay, Automatic Export, Download Files, Speed Boost, Data Deduplication and Developer, as shown in the following figure:
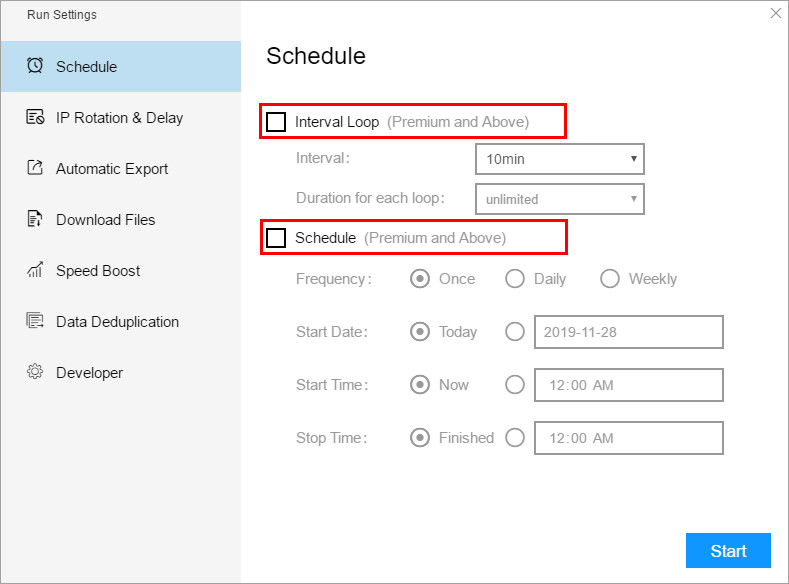
1. Schedule
Schedule means that the user can set the interval loop or set a fixed start and stop time for the task, and periodically collect data according to this time point. Schedule functions include Interval Loop and Schedule.
For more details, please refer to the following tutorial:
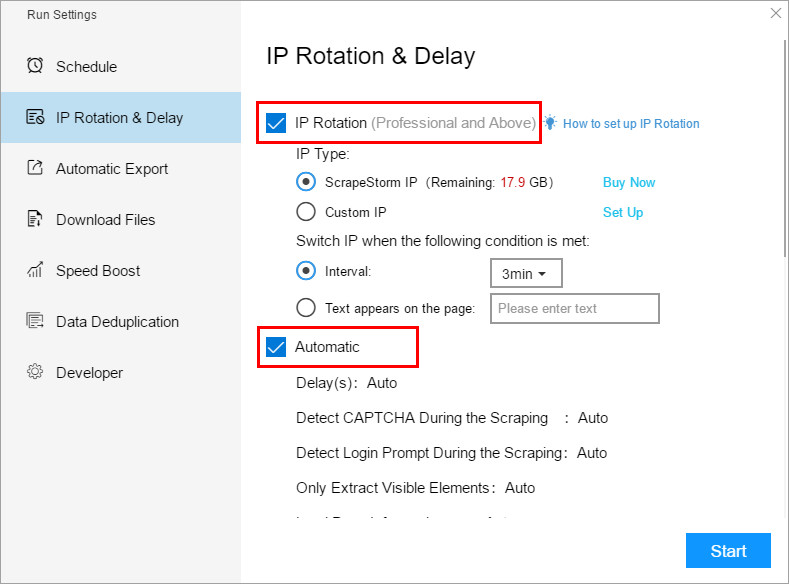
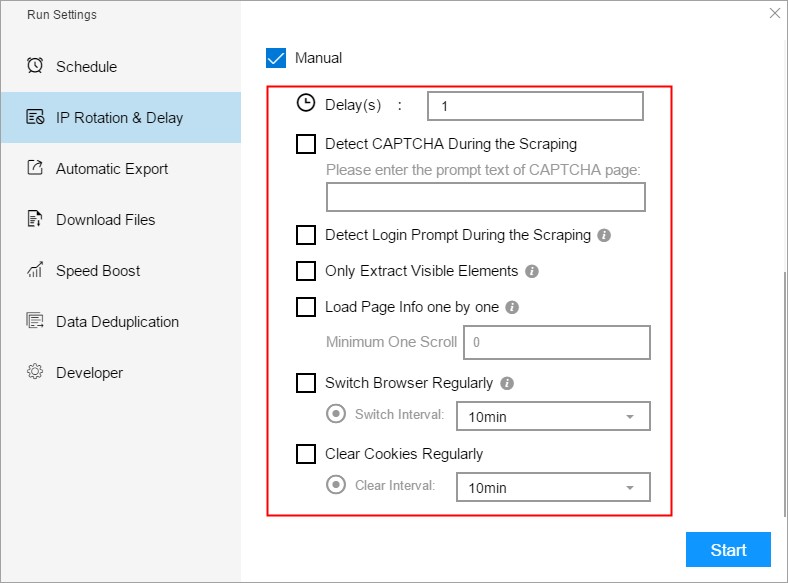
2. IP Rotation & Delay
Anti-blocking settings include IP Rotation, automatic settings and manual settings. This part of the function is mainly used to avoid various website blocking problems that may be encountered.
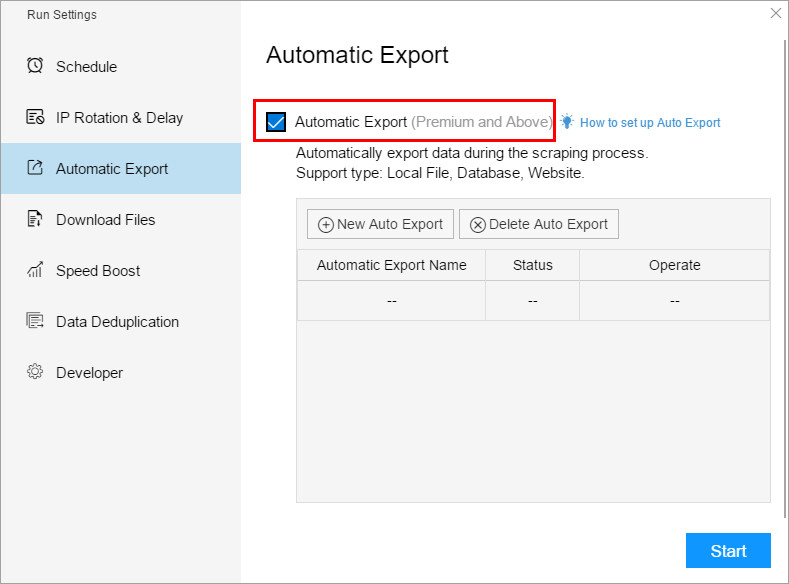
3. Automatic Export
By using this function, you can automatically export the results to local files, databases, and websites during the scraping process. You do not need to wait until the task is finished to manually export the data.
How to set up Automatic Export
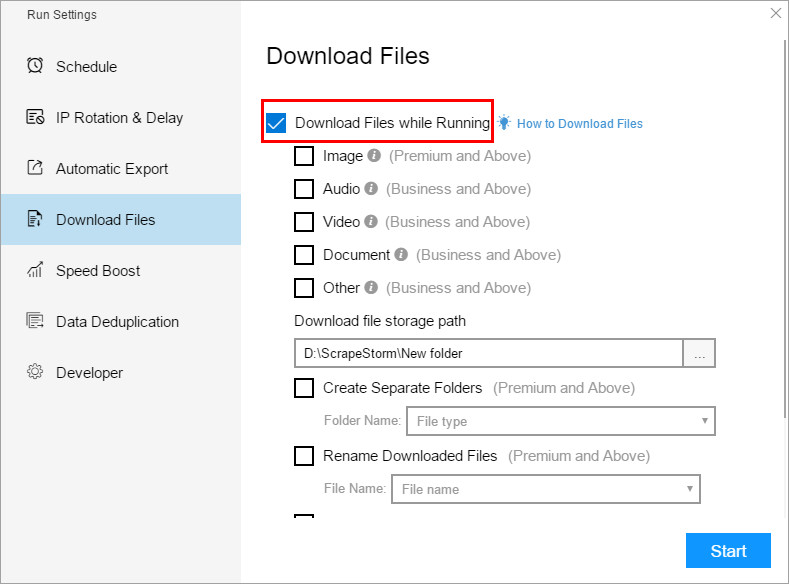
4.Download Files
The software supports downloading files during the scraping process. The file types include: Image, Audio, Video, Document, and Other files. Users can choose a storage path, and create separate folders or rename downloaded files.
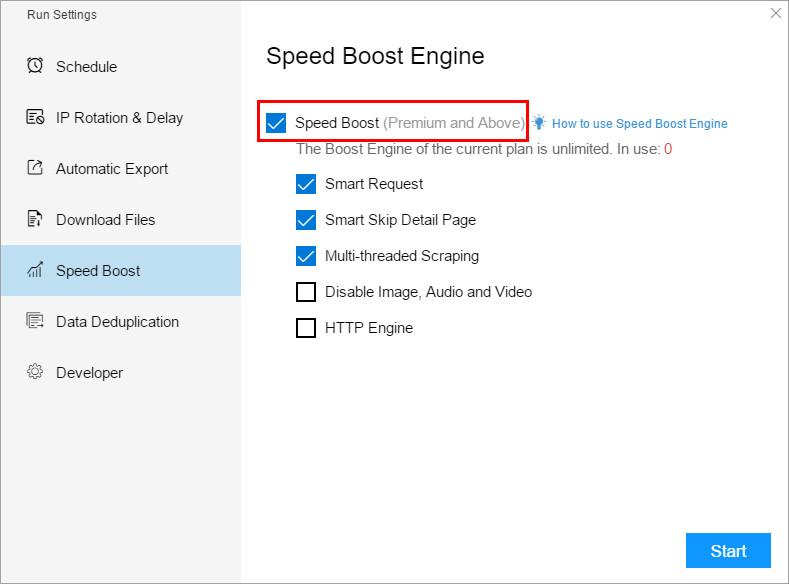
5.Speed Boost
Speed Boost can accelerate tasks. The acceleration effect is related to the loading speed of the web page and the setting of the task. It can usually achieve 3 to 10 times the acceleration effect.
For more details, please refer to the following tutorial:
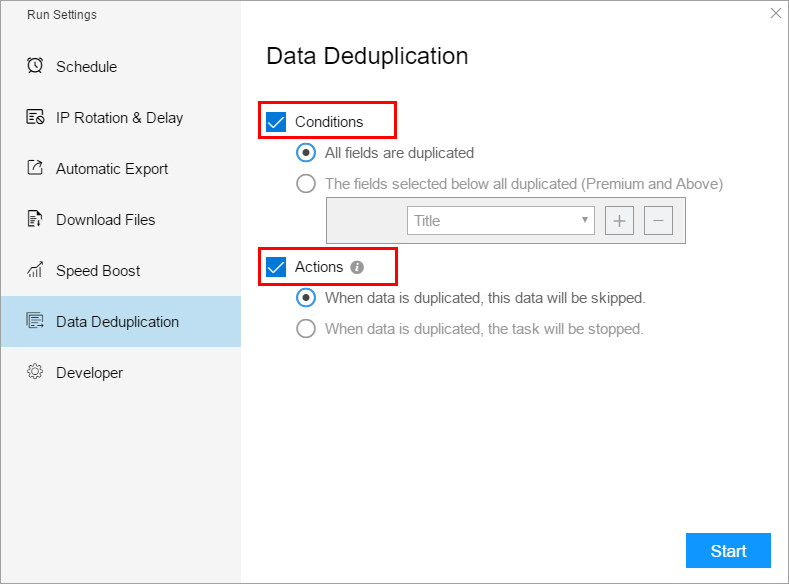
6. Data Deduplication
Data Deduplication refers to filtering out duplicate data that may be encountered during the task scraping process, leaving only valid data. Data Deduplication needs to scrape all the data before it is filtered. Therefore, turning on this function will cause the scraping speed to be slow.
7. Developer
ScrapeStorm supports the Webhook function. By using this function, scraped data can be published to HTTP.
For more details, please refer to the following tutorial: