Data Pipeline | Web Scraping Tool | ScrapeStorm
Abstract:Data pipeline refers to a set of data processing steps and tools used to extract data from a source, transform it, process it, and ultimately load it to a target location within a data system. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Data pipeline refers to a set of data processing steps and tools used to extract data from a source, transform it, process it, and ultimately load it to a target location within a data system. It typically includes stages such as data extraction, cleaning, transformation, and loading (ETL).

Applicable Scene
Data pipelines are used to collect and integrate data from multiple data sources for subsequent data analysis and mining. Real-time or streaming data systems use data pipelines to rapidly process data for analysis and manipulation in real-time or near real-time. Data pipelines can be used not only for data migration and synchronization, but also for data transfer and integration between different applications.
Pros: Data pipelines can automate data processing, ensure data is transformed and loaded according to consistent standards, and improve data quality. Data pipelines are flexible and scalable because you can adjust them to suit your needs, adding new steps or changing the data processing process. Data pipelines enable reliable transmission and processing of data from source to destination, reducing data loss and errors.
Cons: Designing and maintaining data pipelines requires technical expertise and careful planning, and can be time and resource intensive. Data leaks and security issues can occur during data transmission and processing, so security measures must be taken to protect your data. When processing large amounts of data, performance bottlenecks and slowdowns can occur.
Legend
1. Data pipeline.
2. Data pipeline.
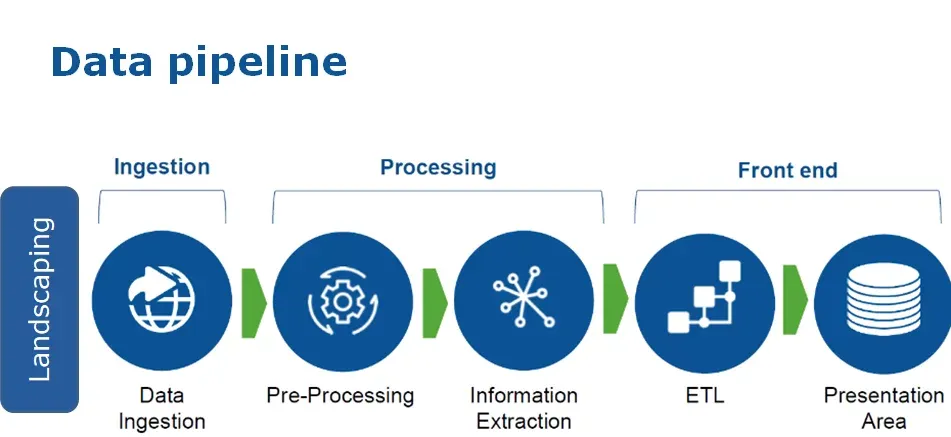
Related Article
Reference Link
https://en.wikipedia.org/wiki/Pipeline_(computing)