Data Classification | Web Scraping Tool | ScrapeStorm
Abstract:Data classification is the process of grouping and organizing data according to specific criteria or attributes. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Data classification is the process of grouping and organizing data according to specific criteria or attributes. This classification can be based on data type, purpose, characteristics, or other relevant factors.
Applicable Scene
Data in a database can be categorized based on specific fields such as date, type, geographic location, and other attributes to make data management and retrieval more efficient. Categorizing documents, files, or other information by topic, content, or format makes it easier to find and use. In the field of data science and analytics, data classification is the basis for exploring data patterns and insights, and data mining can be performed based on specific classification methods.
Pros: Classification makes data easier to manage and maintain, allowing you to quickly find, retrieve, and process the data you need. You can classify and organize data according to different needs to improve work efficiency and data analysis accuracy. You can better understand and leverage your data to discover patterns, trends, and connections.
Cons: Different people may classify data according to different criteria, which can lead to subjectivity and inconsistency in how they are classified. As data volumes grow, maintaining and updating data classifications can become more costly and time-consuming. Over-segmentation can make your classification system too complex and difficult to manage and use.
Legend
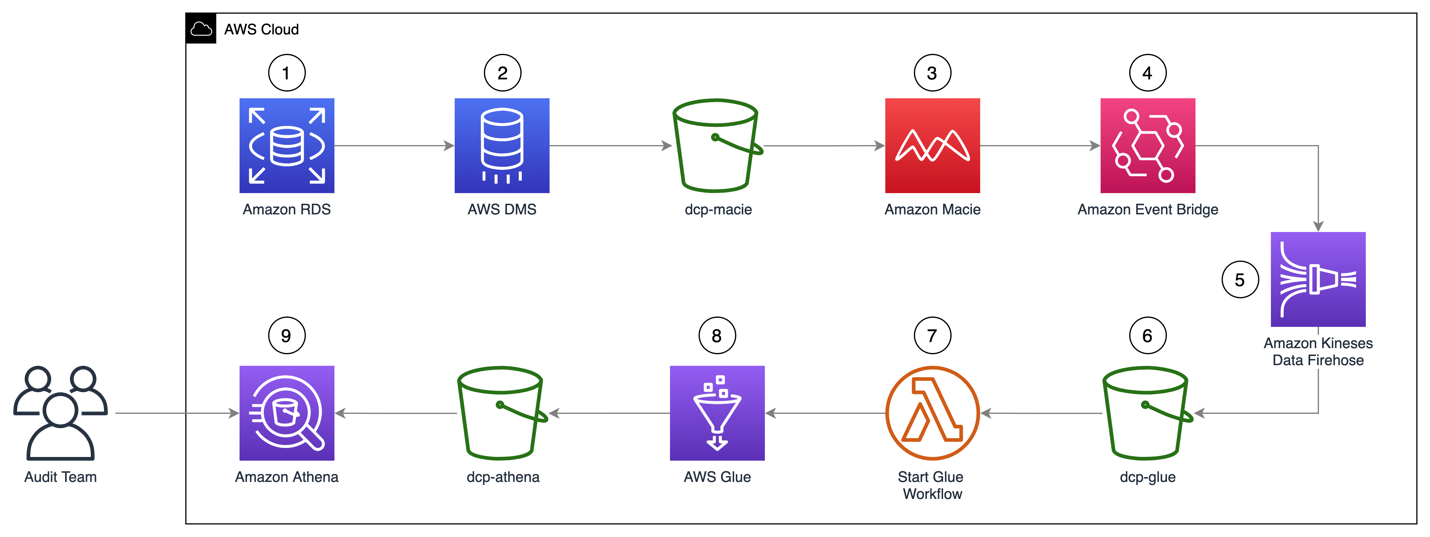
1. How to classify data in an Amazon RDS database using Amazon Macie.
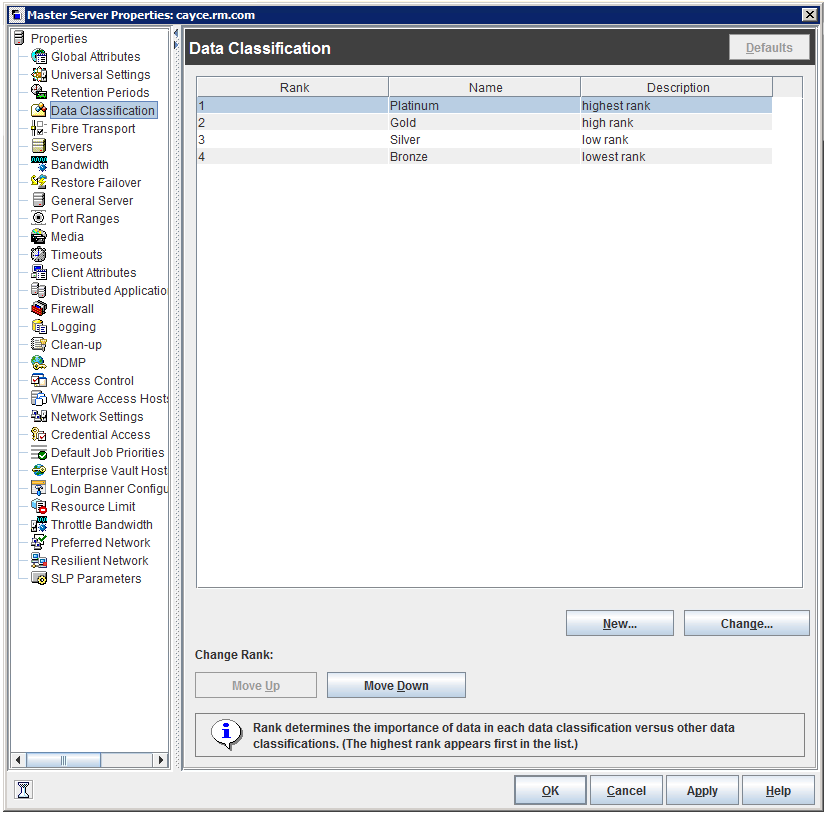
2. Data Classification properties.
Related Article
Reference Link
https://en.wikipedia.org/wiki/Data_classification_(business_intelligence)
https://www.techtarget.com/searchdatamanagement/definition/data-classification