Data sampling | Web Scraping Tool | ScrapeStorm
Abstract:Data sampling is the process of selecting or extracting a portion of data from a large data set to represent the entire data set. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
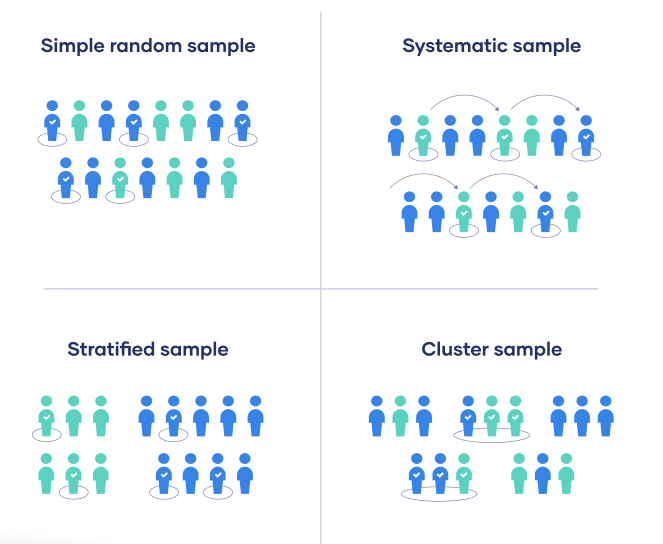
Data sampling is the process of selecting or extracting a portion of data from a large data set to represent the entire data set. The purpose of sampling is to reduce the amount of data for ease of processing while maintaining a representative representation of the entire data distribution. Data sampling is a critical step in data analysis, and a variety of sampling methods can be used, including random sampling, stratified sampling, oversampling, and undersampling, depending on the specific analytical needs and characteristics of the data set. These methods help process large data more efficiently while maintaining an effective representation of the data population.

Applicable Scene
Data sampling is suitable for a variety of situations, including data mining, statistical analysis, market research, and machine learning. For large datasets, sampling reduces computational and memory requirements and speeds up the analysis process.
Pros: Data sampling helps accelerate analysis, lower costs, reduce computing resource requirements, and provides efficient results when processing large data.
Cons: Sampling methods should be chosen carefully, as inappropriate sampling can lead to loss of information and bias. Additionally, sampling may not capture minorities or anomalies.
Legend
1. How to deal with unbalanced data: Downsampling.
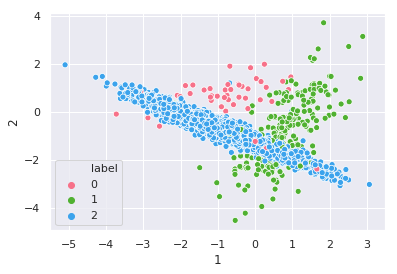
2. Data sampling.
Related Article
Reference Link
https://www.techtarget.com/searchbusinessanalytics/definition/data-sampling
https://support.google.com/analytics/answer/2637192?hl=en#zippy=%2Cin-this-article