Push-Pull Model | Web Scraping Tool | ScrapeStorm
Abstract:Push-Pull Model is an architectural pattern that describes the data transmission mechanism between system components, defining the interaction between data producers (sources) and data consumers (targets). ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
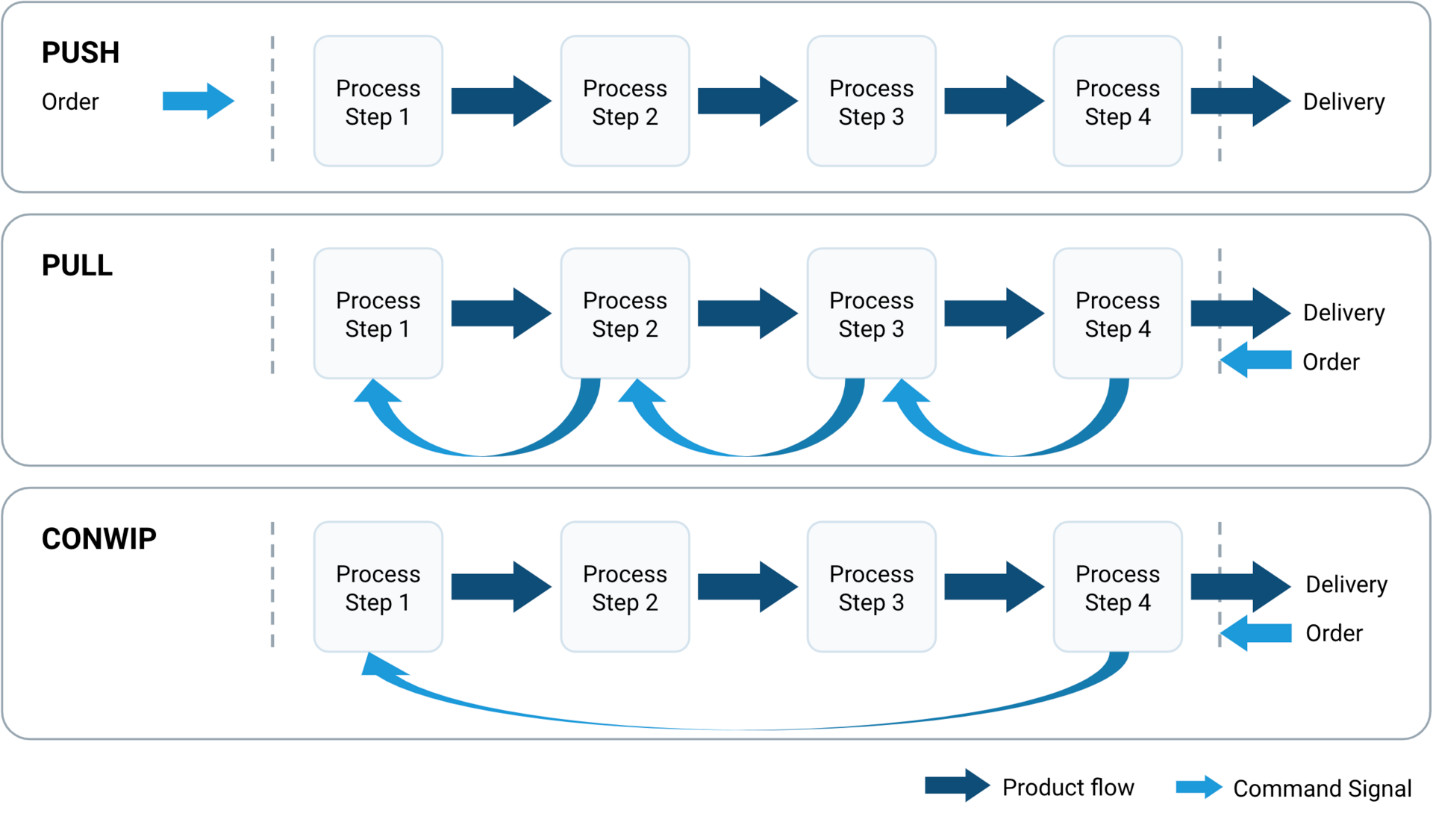
Push-Pull Model is an architectural pattern that describes the data transmission mechanism between system components, defining the interaction between data producers (sources) and data consumers (targets). In Push mode, the data source actively sends data to the target; in Pull mode, the data consumer actively requests or retrieves data from the source. Practical systems often employ a hybrid approach—the Push-Pull Model—combining the two transmission methods dynamically or statically based on business requirements, network conditions, real-time demands, and system load to optimize data flow efficiency, reliability, and resource utilization. This model is widely applied in message queue systems, data synchronization mechanisms, stream processing platforms, and distributed caching scenarios.
Applicable Scene
The Push-Pull Model is extensively used in various architectures requiring efficient data transmission between different system components. In message queue systems, producers push to queues while consumers pull for processing, achieving decoupling and peak load leveling; in data synchronization scenarios, source systems push change data while target systems periodically pull full data for verification; in stream processing platforms, data sources continuously push real-time streams while processing engines pull batch data on demand for window computations; in distributed caching systems, cache nodes actively push invalidation notifications while application servers pull latest data as needed; in IoT environments, sensor devices push real-time monitoring data while central control systems pull historical data on demand for trend analysis. This model is particularly suitable for distributed systems that need to balance real-time responsiveness with system load, handle asymmetric processing capabilities, or operate under unstable network conditions.
Pros: The greatest advantage of the push-pull data model lies in its high flexibility and resource optimization capabilities. The push mode ensures rapid data delivery in high-real-time scenarios, while the pull mode avoids the overhead of continuous polling on the target end or the risk of overloaded pushes on the source end. The combination of these two approaches enables fine-grained system load management. This model strengthens the decoupling between producers and consumers, allowing both to scale and maintain independently without needing to be aware of each other’s specific state. In terms of fault tolerance, the pull mode supports breakpoint resumption for consumers, while the push mode, combined with an acknowledgment mechanism, ensures reliable data delivery, significantly improving the robustness of the distributed system. Furthermore, the push-pull hybrid design can adapt to heterogeneous environments—whether it’s nodes with varying processing capabilities, fluctuating network bandwidth, or dynamically changing business loads, it can maintain the stability and efficiency of data transmission under complex conditions..
Cons: The primary challenges of the Push-Pull Model stem from the systemic risks introduced by its architectural complexity. Implementing both push and pull mechanisms simultaneously requires designing sophisticated coordination logic, state management, and mode-switching strategies, significantly increasing development and operational costs. Regarding data consistency, hybrid models are prone to issues such as out-of-order data arrival, duplicate processing, or timing conflicts, necessitating additional mechanisms like version control and idempotency design to ensure correctness. Uncertainty in latency characteristics is another prominent issue—the inherent delay introduced by Pull mode polling intervals, combined with potential backlogs in Push mode during network congestion, makes end-to-end latency difficult to predict and optimize. Additionally, the extra communication overhead required for mode selection, state synchronization, and flow control may become performance bottlenecks in high-frequency interaction scenarios. The diversified data flow paths further complicate problem localization and anomaly troubleshooting, particularly when tracing data loss or duplication issues across multi-component push-pull hybrid chains.
Legend
1. Push–Pull Model.
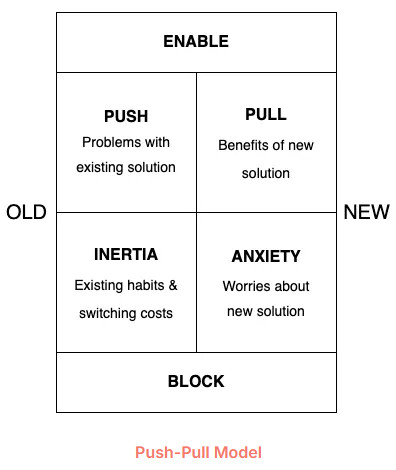
2. Push–Pull Strategy.