Data Refresh Policy | Web Scraping Tool | ScrapeStorm
Abstract:Data Refresh Policy refers to a set of rules and mechanisms used to manage the update, synchronization, and invalidation of data within storage systems, defining the methods and frequency for maintaining consistency between source and target data. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Data Refresh Policy refers to a set of rules and mechanisms used to manage the update, synchronization, and invalidation of data within storage systems, defining the methods and frequency for maintaining consistency between source and target data. This policy determines when and how changes from source data are propagated to downstream systems such as caches, data warehouses, indexes, or replicas, encompassing various modes including full refresh, incremental refresh, real-time refresh, and scheduled refresh. Data Refresh Policy is a core decision element in data architecture design, directly impacting system data consistency, performance, resource consumption, and user experience. It plays a critical role in areas such as caching systems, data warehouses, search engines, and distributed databases.
Applicable Scene
Data Refresh Policy is widely applied in various data-intensive systems that require maintaining consistency across multiple data copies. In caching systems, the policy determines when to refresh the cache from source databases to balance data freshness with access performance; in data warehouse scenarios, ETL processes perform incremental data extraction from business databases or full rebuilds based on refresh policies; in search engine index maintenance, the policy controls when document updates become visible to searches; in distributed database replication, the policy defines synchronization methods and latency tolerance between master and slave nodes; in real-time dashboard applications, the policy determines data visualization update frequencies to meet business monitoring requirements. This strategy is particularly suitable for scenarios requiring trade-offs between data consistency, system performance, and operational costs.
Pros: The core advantage of Data Refresh Policy lies in providing systems with a configurable balance between data consistency, performance, and resource consumption. By flexibly selecting full, incremental, or real-time refresh modes, systems can be precisely optimized for different data characteristics and business requirements—cold data uses low-frequency refresh to save resources, while hot data employs high-frequency or real-time refresh to ensure freshness. Clear refresh policies simplify data lifecycle management, enabling operations teams to predict and control system load caused by data synchronization. In caching scenarios, well-designed refresh policies (such as protection mechanisms against cache penetration and cache breakdown) can significantly improve hit rates and reduce backend storage pressure. Furthermore, standardized refresh policies provide predictable consistency guarantees for distributed systems, helping developers make informed trade-offs between eventual consistency and strong consistency that align with business needs.
Cons: The design and implementation of data refresh strategies face multiple complexities and potential risks. Choosing the refresh frequency often presents a dilemma—too high a frequency leads to wasted system resources and performance degradation, while too low a frequency results in outdated data, impacting the accuracy of business decisions. In distributed environments, refresh strategies struggle to simultaneously satisfy the CAP theorem (consistency, availability, and partition tolerance), necessitating compromises. Full refresh on large datasets can generate significant I/O overhead and network load, affecting production system stability; incremental refresh, while resource-efficient, requires complex change capture mechanisms (such as CDC) and state management, increasing system complexity. Uncertainty regarding refresh timing can lead to data windows, potentially causing serious problems in scenarios with stringent consistency requirements, such as financial transactions and real-time monitoring. Furthermore, nested refresh strategies within multi-layered caching architectures can easily create cascading effects, making data latency issues difficult to diagnose and optimize.
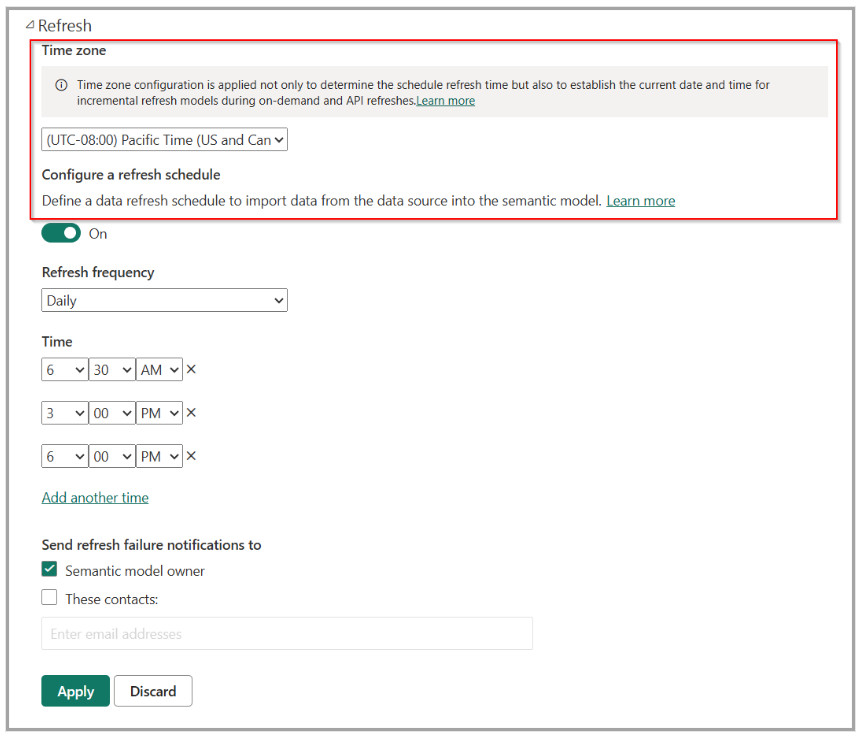
Legend
1. Incremental refresh.

2. Data refresh.
Related Article
Reference Link
https://docs.tabulareditor.com/tutorials/incremental-refresh/incremental-refresh-about.html
https://www.sciencedirect.com/science/article/pii/S0167923604002532