Vertical Crawling | Web Scraping Tool | ScrapeStorm
Abstract:Vertical Crawling is a web crawling technique that targets data collection within a specific domain, industry, or topic. Unlike general search engines that broadly cover all types of web pages, vertical crawling focuses on particular verticals such as e-commerce, job listings, real estate, news, or academic papers. It uses predefined site lists, structured parsing rules, and domain knowledge to accurately extract key information and build high-quality structured datasets for specific scenarios. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Vertical Crawling is a web crawling technique that targets data collection within a specific domain, industry, or topic. Unlike general search engines that broadly cover all types of web pages, vertical crawling focuses on particular verticals such as e-commerce, job listings, real estate, news, or academic papers. It uses predefined site lists, structured parsing rules, and domain knowledge to accurately extract key information and build high-quality structured datasets for specific scenarios.
Applicable Scene
Vertical crawling is widely used in industry data analysis, price monitoring, talent recruitment, real estate market research, academic literature aggregation, and news sentiment analysis. In e-commerce, it captures product prices, sales, and reviews for competitive analysis. In recruitment, it collects job postings and salary data for labor market trends. In real estate, it gathers property information and price changes for investment research. In academia, it extracts paper metadata and citation relationships to build knowledge graphs.
Pros: The core advantage of vertical crawling is its precision and structured data output. By focusing on a specific domain, crawlers can design detailed parsing rules for particular page templates, extracting standardized data with consistent formats and reducing cleaning costs. Compared to general crawlers, it consumes fewer resources and allows for easier customization. Additionally, it can access deep, domain-specific information that general search engines cannot easily reach.
Cons: Vertical crawling faces stability challenges when target websites undergo redesigns or update anti-crawling measures. Since parsing rules depend heavily on specific page structures, changes to page templates can cause extraction failures, requiring frequent maintenance. Each target site typically needs separate configuration, leading to rising maintenance costs as scale grows. Modern websites with dynamic loading, asynchronous requests, and anti-crawling mechanisms (IP blocking, CAPTCHAs) also increase technical complexity. Finally, collection activities must comply with site terms of service and relevant regulations to avoid compliance risks.
Legend
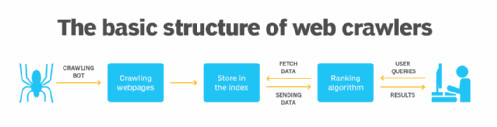
1. High-level architecture of a standard Web crawler.
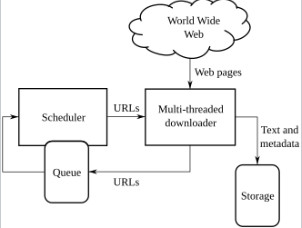
2. The basic structure of web crawlers.