Adaptive Crawling Strategy | Web Scraping Tool | ScrapeStorm
Abstract:An Adaptive Crawling Strategy is a crawling method used in web crawlers or data collection systems that dynamically evaluates factors such as the update frequency, importance, response status, and resource constraints of target websites to flexibly adjust crawling targets, frequency, and priority. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
An Adaptive Crawling Strategy is a crawling method used in web crawlers or data collection systems that dynamically evaluates factors such as the update frequency, importance, response status, and resource constraints of target websites to flexibly adjust crawling targets, frequency, and priority. Unlike traditional fixed-schedule crawling, this strategy incorporates real-time data update status and system load as feedback, aiming to maintain an optimal balance between efficiency and comprehensiveness. It plays a critical role in fields requiring large-scale and continuous information collection, such as search engines, data aggregation platforms, and monitoring systems.
Applicable Scene
The Adaptive Crawling Strategy is well-suited for data collection environments involving numerous websites or APIs with significantly varying update frequencies, such as search engine index updates, price and inventory monitoring for news or e-commerce sites, social media analysis, periodic open data collection, and competitor information tracking. It is particularly effective in systems where limited network bandwidth or computational resources necessitate prioritizing high-value information.
Pros: The Adaptive Crawling Strategy can automatically adjust crawling intervals based on page update frequency and historical crawling results, reducing unnecessary re-acquisition and enabling efficient use of bandwidth and computational resources. It also supports priority ranking based on importance and freshness, allowing rapid collection of high-value information. Additionally, its ability to detect failures or response delays and modify behavior contributes to load reduction on target websites and improved overall system stability.
Cons: The strategy design tends to be complex, requiring advanced expertise to design and fine-tune algorithms for update frequency estimation and importance evaluation. During initial stages, insufficient historical data may make optimal crawling decisions challenging. Furthermore, using incorrect evaluation metrics risks missing important pages or causing crawling bias toward specific content.
Legend
1. Flowchart of adaptive data crawling..
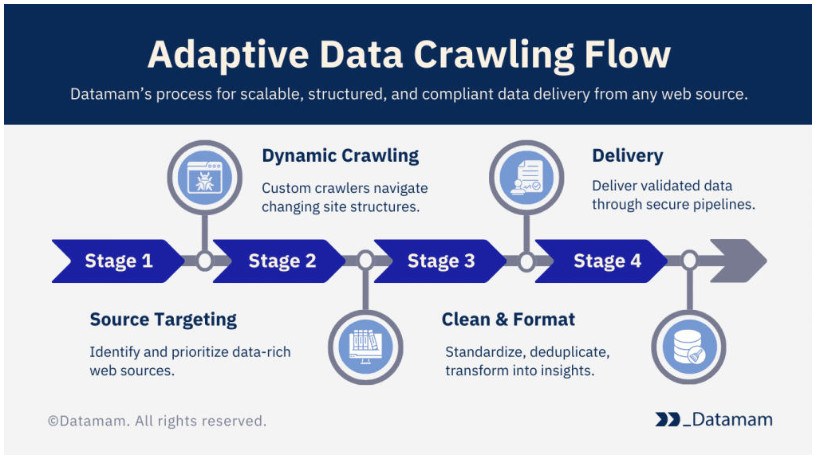
2. Flowchart of adaptive data crawling..