Data Deduplication | Web Scraping Tool | ScrapeStorm
Abstract:Data deduplication is a data optimization technology that identifies and eliminates duplicate copies of data in a data set, retaining only a unique copy of the data and its reference, thereby reducing storage space usage, reducing data transmission volume and improving data management efficiency. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
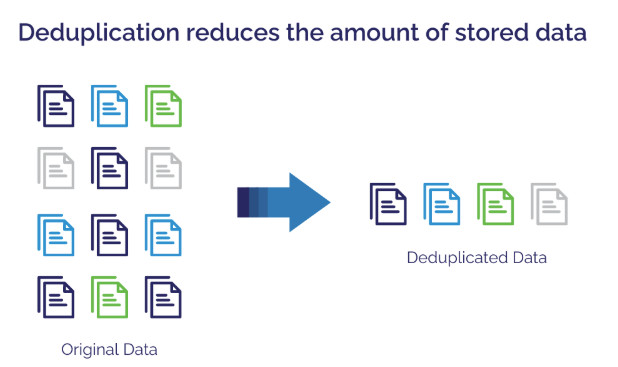
Data deduplication is a data optimization technology that identifies and eliminates duplicate copies of data in a data set, retaining only a unique copy of the data and its reference, thereby reducing storage space usage, reducing data transmission volume and improving data management efficiency.
Applicable Scene
It is suitable for scenarios with high data duplication, such as large-scale data storage systems (such as enterprise data centers and cloud storage services), data backup and archiving scenarios (reducing backup storage space), and network data transmission (such as file sharing and email systems to reduce transmission bandwidth consumption).
Pros: Data deduplication can significantly save storage space, improve data transmission efficiency and simplify data management processes.
Cons: Data deduplication will increase system computing overhead, may affect data recovery, and has high technical implementation complexity.
Legend
1. Data deduplication.
2. Python list deduplication code example.

Related Article
Reference Link
https://en.wikipedia.org/wiki/Data_deduplication
https://www.ibm.com/think/topics/data-deduplication
https://www.techtarget.com/searchstorage/definition/data-deduplication