Multi-source Data Fusion | Web Scraping Tool | ScrapeStorm
Abstract:Multi-source data fusion refers to techniques and techniques to integrate different types and types of data into consistent information. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Multi-source data fusion refers to techniques and techniques to integrate different types and types of data into consistent information. Data types include sensor observations, remote sensing images, geospatial information, text and numerical data, and more IoT There are various information acquired from equipment and social media. It aims at deriving comprehensive and reliable knowledge that is not available in a single data source.
Applicable Scene
Multi-source data fusion is widely applied to the prediction of weather and disaster prevention, crop management in agriculture, traffic flow analysis in urban planning, diagnosis support in medical care, and further military and security sectors. For example, meteorological observation enables more accurate prediction by integrating ground observation data and satellite observation data. In the field of agriculture, the combination of soil sensors, drone images, and meteorological information can be used to determine optimal fertilization and irrigation.
Pros: The greatest advantage is that it complements the lack of information and bias and leads to more accurate analytical results. By combining different sensors and data sources, it is possible to grasp the phenomenon which is difficult to be caught by the single data. And AI The combination of machine learning and machine learning makes it possible to find complex patterns and improve the prediction model, which leads to decision support in real time. In addition, Merritt is a big point that can create new knowledge and value by merging heterogeneous data.
Cons: There are several challenges in multi-source data fusion. First, because the data format, resolution, and acquisition timing are different, preprocessing and normalization are necessary for integration, and it takes time and cost. If there is a difference in data quality, erroneous integration has the risk of lowering reliability. Moreover, in order to deal with large and diverse data, high technical power is required for system construction and algorithm design. In addition, data sharing can be restricted from a point of view of privacy and security.
Legend
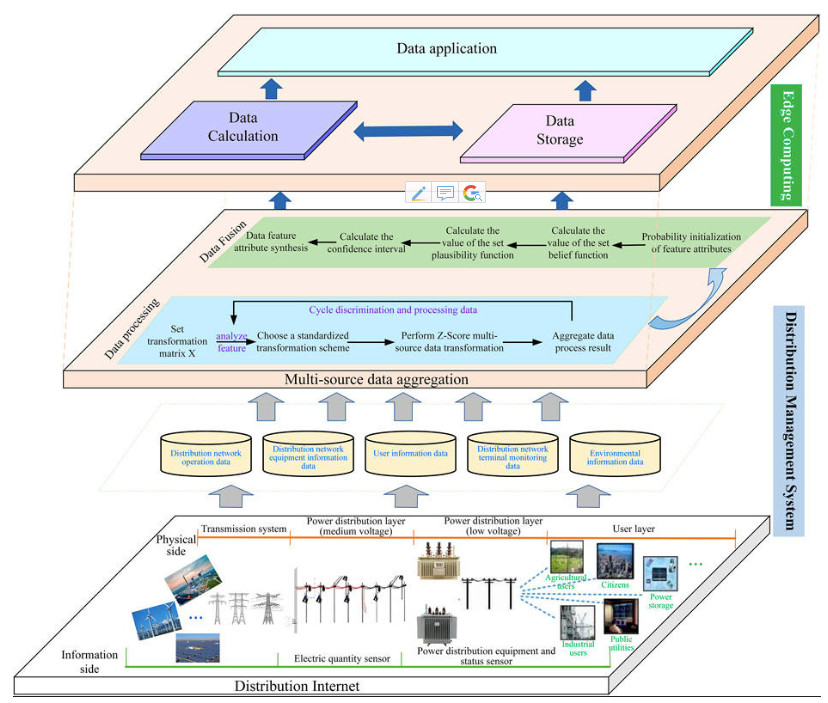
1. Multisource data processing and fusion architecture.
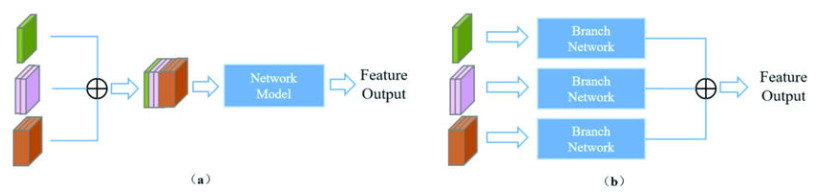
2. Multi-source data fusion (a) layer stacking and (b) feature fusion based on deep learning classification network.
Related Article
Reference Link
https://www.buffalo.edu/cimif/center/what-is-MIF.html
https://traversals.com/products/multi-source-data-fusion-platform/
https://www.frontiersin.org/journals/energy-research/articles/10.3389/fenrg.2022.891867/full