Data Source Identification | Web Scraping Tool | ScrapeStorm
Abstract:Data Source Identification refers to the systematic identification, classification, and organization of information such as the source, storage location, data format, update frequency, and responsible person of various types of data existing within and outside an organization or system. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Data Source Identification refers to the systematic identification, classification, and organization of information such as the source, storage location, data format, update frequency, and responsible person of various types of data existing within and outside an organization or system. Its core objective is to lay a solid foundation for subsequent data integration, analysis, governance, and security management. In scenarios such as data warehouse construction, data pipeline design, master data management, and artificial intelligence model development, it is often considered a critical first step.
Applicable Scene
Data source identification is suitable for cross-departmental data application scenarios such as pre-launch status quo assessments, data integration projects, cloud migration planning, data governance system construction, and BI platform development. Especially in environments where databases are scattered across different departments and contain multiple sources such as external APIs, log files, IoT sensor data, and SaaS application data, data source identification helps to comprehensively understand the data landscape, clarify the dependencies between data, and is an important prerequisite for achieving system integration and unified management.
Pros: By conducting data source identification, the storage location and responsibility for data assets can be clarified, and issues such as data duplication and information silos can be identified. Simultaneously, it helps optimize subsequent ETL/ELT design and metadata management processes, laying the foundation for improved data quality and the development of security strategies. Ultimately, it enhances the transparency of data usage and improves the overall organizational decision-making accuracy and operational efficiency.
Cons: Preliminary research often requires significant time and human resources, especially in large organizations where cross-departmental coordination is complex. Furthermore, in situations of frequent system environment changes, information may quickly become obsolete if the identification results are not continuously updated. Without a robust metadata management mechanism, the identification results may remain merely a formalized list, failing to truly support actual business applications.
Legend
1.Data source identification in network traffic analysis.

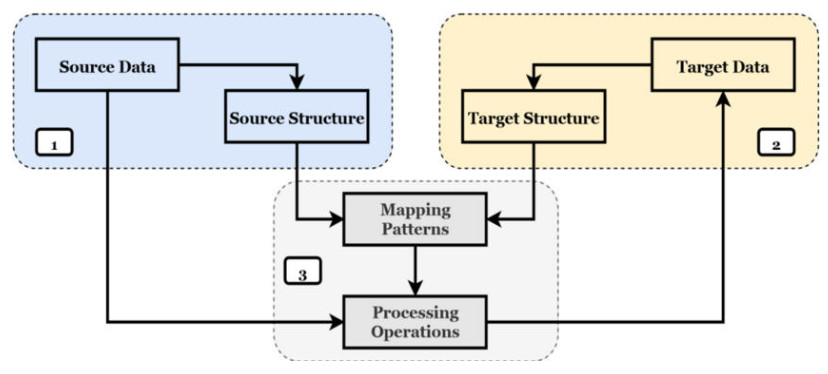
2. Data mapping process: Identify the source end and the target end, and associate the two structures through a mapping pattern.
Related Article
Reference Link
https://en.wikipedia.org/wiki/Data_source_name
https://www.ibm.com/docs/en/iii/10.0.0?topic=architecture-data-sources