Deep Crawling | Web Scraping Tool | ScrapeStorm
Abstract:Deep Crawling refers to a technical method in which a web crawler not only collects information from the homepage or surface pages of a target website but also recursively follows links within pages to continuously access and collect data from deeper levels of the site. Unlike shallow crawling, which only captures surface-level pages, deep crawling can penetrate a website's directory structure, pagination navigation, category links, and dynamically loaded content, thereby obtaining more comprehensive and complete data resources. This technique typically requires the integration of link deduplication, crawling strategy optimization, anti-scraping mechanism handling, and distributed scheduling to efficiently and stably complete large-scale data collection tasks. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
Deep Crawling refers to a technical method in which a web crawler not only collects information from the homepage or surface pages of a target website but also recursively follows links within pages to continuously access and collect data from deeper levels of the site. Unlike shallow crawling, which only captures surface-level pages, deep crawling can penetrate a website’s directory structure, pagination navigation, category links, and dynamically loaded content, thereby obtaining more comprehensive and complete data resources. This technique typically requires the integration of link deduplication, crawling strategy optimization, anti-scraping mechanism handling, and distributed scheduling to efficiently and stably complete large-scale data collection tasks.
Applicable Scene
Deep crawling is widely used in scenarios such as search engine indexing, big data analytics, market intelligence collection, academic research, and vertical domain data aggregation. In the search engine field, deep crawling is a core technical means for building web page indexes and improving search result coverage and timeliness. In e-commerce and business intelligence analysis, deep crawling can be used to capture multi-level data such as product details, user reviews, and price change histories, supporting competitive analysis and pricing strategy formulation. In academic research and knowledge graph construction, deep crawling can obtain deep-level structured information from sources such as academic databases, thesis websites, and government open data platforms. Additionally, in areas such as news aggregation, social media monitoring, job posting collection, and real estate data integration, deep crawling is also a key method for achieving data completeness and timeliness.
Pros: The core advantage of deep crawling lies in its ability to obtain deep data not accessible through surface links, significantly improving the completeness and coverage of data collection. By recursively traversing a website’s multi-level page structure, deep crawling can uncover rich information hidden behind mechanisms such as pagination, filtering, and related recommendations, providing a high-quality data foundation for subsequent analysis and applications. Compared to manual collection or API calls, deep crawling enables automated, large-scale data acquisition, greatly reducing the time and labor costs of data collection. Furthermore, when combined with incremental crawling and update strategies, deep crawling can achieve continuous monitoring and dynamic updates of target websites, maintaining data freshness and timeliness.
Cons: Deep crawling faces multiple challenges and limitations during implementation. First, deep crawling places significant access pressure on the target website’s server resources. Without reasonable access frequency control, it may trigger the website’s anti-scraping mechanisms, leading to IP bans, CAPTCHA challenges, or legal risks. Second, as crawling depth increases, the number of pages grows exponentially, and link deduplication, task scheduling, and storage management face high system complexity and resource consumption. Additionally, modern websites widely employ technologies such as JavaScript dynamic rendering, asynchronous loading, and single-page application (SPA) architectures. Traditional deep crawling methods based on static HTML struggle to directly parse such sites, requiring the introduction of additional technical measures such as headless browsers. Finally, data collection activities involved in deep crawling must comply with relevant laws, regulations, and the target website’s robots.txt protocol. Unauthorized large-scale crawling may lead to data security and copyright disputes.
Legend
1. High-level architecture of a standard Web crawler.
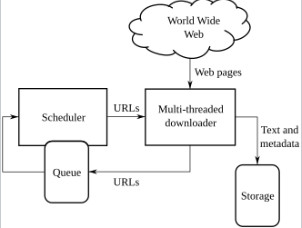
2. Deep crawling.