Robots.txt | Web Scraping Tool | ScrapeStorm
Abstract:Robots.txt means that the website can create a robots.txt file to tell the search engine which pages can be crawled and which pages cannot be crawled, and the search engine reads the robots.txt file to identify whether the page is allowed to be crawled. ScrapeStormFree Download
ScrapeStorm is a powerful, no-programming, easy-to-use artificial intelligence web scraping tool.
Introduction
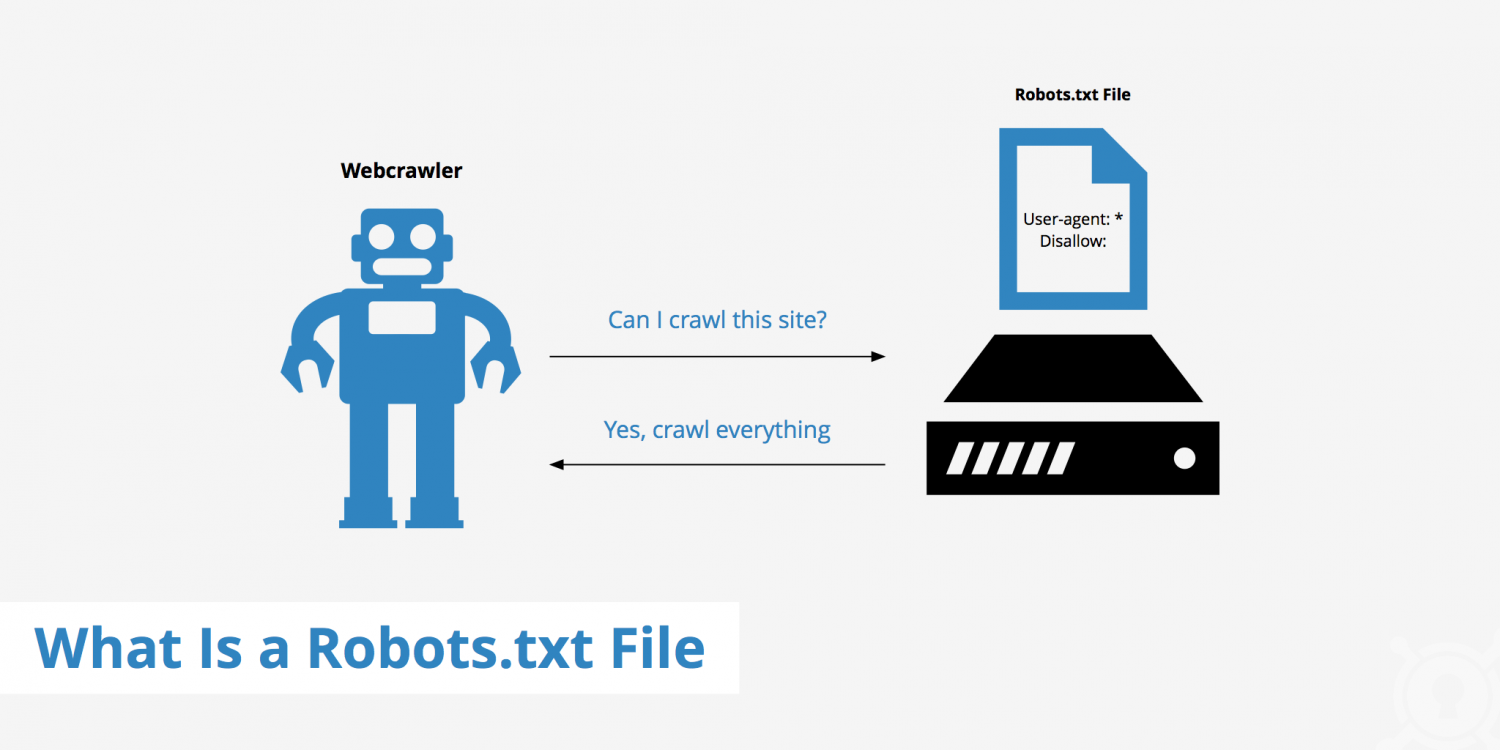
Robots.txt means that the website can create a robots.txt file to tell the search engine which pages can be crawled and which pages cannot be crawled, and the search engine reads the robots.txt file to identify whether the page is allowed to be crawled. However, this is not a firewall, and it has no enforcement power. Search engines can completely ignore the robots.txt file and grab a snapshot of the web page.

Applicable Scene
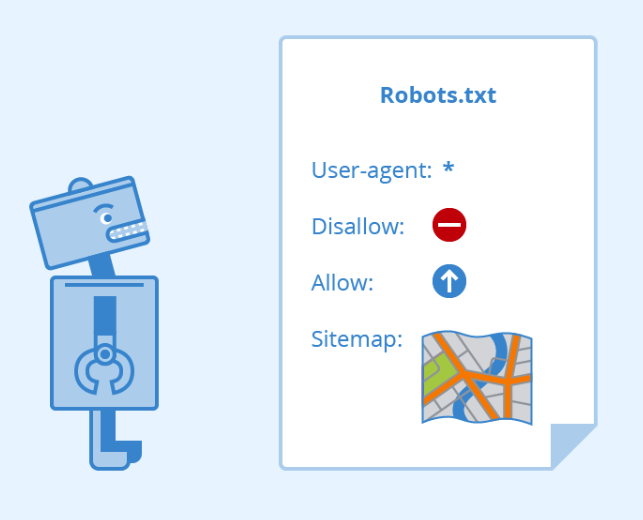
The purpose of Robots.txt is to help website administrators control the access of search engine spiders to protect private content, reduce server load, or direct spiders to specific parts of the site. Robots.txt specifies some instructions, such as “User-agent” (specify spiders) and “Disallow” (specify prohibited access paths), to instruct search engine spiders how to crawl the website.
This protocol is important for both search engine optimization (SEO) and website security, and webmasters can use robots.txt to specify which content is exposed to search engines and which should not be indexed.
Pros: Robots.txt allows website administrators to explicitly control access to search engine spiders, thus maintaining the privacy and security of website content. This helps reduce server load and improve website performance, while allowing different rules to be customized for different search engines to more finely control their crawling behavior. Additionally, Robots.txt improves the quality of search results by preventing search engines from repeatedly indexing multiple copies of the same content.
Cons: First of all, it is not a security measure for the website because not all search engines follow these rules and some malicious crawlers may not. Second, although it is possible to specify which pages should not be crawled, this does not mean that the page content is private. Robots.txt is just a guide for search engines and not a real security measure. Furthermore, it cannot prevent users from directly accessing banned pages, as it is only a guide for search engine spiders. Finally, Robots.txt needs to be configured correctly, otherwise search engines may not be able to index important content of the website, and it needs to be configured and maintained carefully.
Legend
1. Robots.txt
2. What is a Robots.txt file
Related Article
Reference Link
https://en.wikipedia.org/wiki/Robots.txt
https://developers.google.com/search/docs/crawling-indexing/robots/intro
https://developers.google.com/search/docs/crawling-indexing/robots/create-robots-txt